python教程技术文章
-
 使用np.memmap时,result[:]=a[:]-b[:]会意外创建完整中间数组导致OOM;应改用支持out=参数的ufunc(如np.subtract)直接写入磁盘映射内存,避免RAM缓存膨胀。411 收藏
使用np.memmap时,result[:]=a[:]-b[:]会意外创建完整中间数组导致OOM;应改用支持out=参数的ufunc(如np.subtract)直接写入磁盘映射内存,避免RAM缓存膨胀。411 收藏 -
 最安全直观的方式是对单列用df[col_name].apply(func);df.apply(func,axis=1)是按行操作而非按列,易导致报错或结果错误;axis=0(默认)才按列处理,但需函数适配Series输入。411 收藏
最安全直观的方式是对单列用df[col_name].apply(func);df.apply(func,axis=1)是按行操作而非按列,易导致报错或结果错误;axis=0(默认)才按列处理,但需函数适配Series输入。411 收藏 -
文章 · python教程 | 1个月前 | 性能优化 · 异步编程 · fastapi · 生产实践 · Python教程 · API服务 · Python API服务 FastAPI asyncio httpx 生产实践 lifespan BackgroundTasks run_in_threadpool
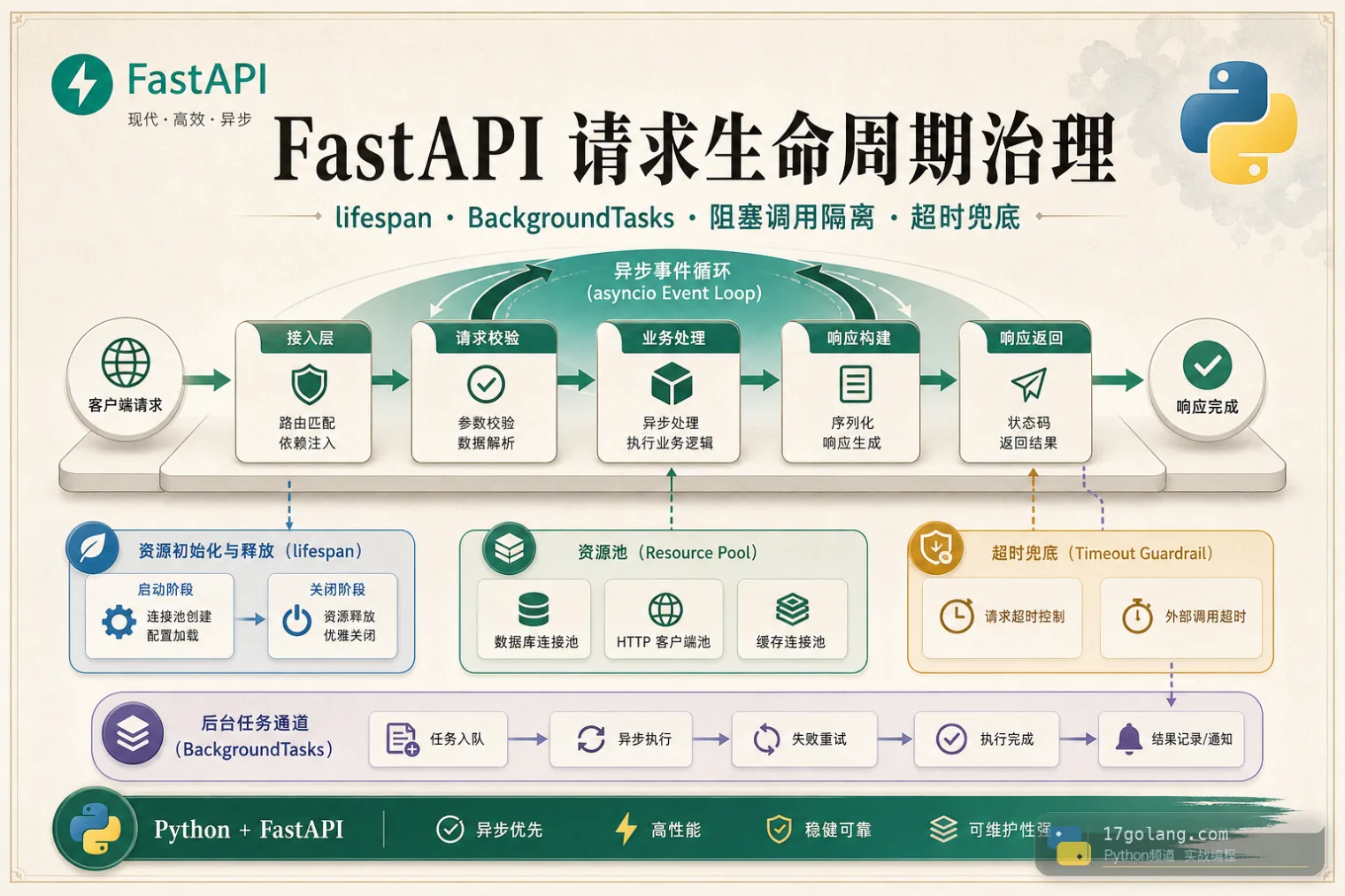 从 Python FastAPI 线上慢请求和后台任务丢失入手,讲清 lifespan 资源管理、阻塞调用隔离、BackgroundTasks 边界、超时和上线检查。411 收藏
从 Python FastAPI 线上慢请求和后台任务丢失入手,讲清 lifespan 资源管理、阻塞调用隔离、BackgroundTasks 边界、超时和上线检查。411 收藏 -
 query()方法返回的是惰性求值的可迭代对象,即Query实例,非原生生成器或列表;遍历、list()、first()等操作才触发SQL执行,多次遍历会重复查询。410 收藏
query()方法返回的是惰性求值的可迭代对象,即Query实例,非原生生成器或列表;遍历、list()、first()等操作才触发SQL执行,多次遍历会重复查询。410 收藏 -
 <p>/是真除法返回浮点数,%是取模运算返回非负余数;判断奇偶、轮询索引等必须用%;Python中%与//互补满足a==(a//b)*b+(a%b),divmod封装该关系。</p>410 收藏
<p>/是真除法返回浮点数,%是取模运算返回非负余数;判断奇偶、轮询索引等必须用%;Python中%与//互补满足a==(a//b)*b+(a%b),divmod封装该关系。</p>410 收藏 -
 因为单页应用(SPA)的主体内容由JavaScript动态渲染,requests.get()仅获取初始HTML骨架,真实数据藏在后续API调用中。410 收藏
因为单页应用(SPA)的主体内容由JavaScript动态渲染,requests.get()仅获取初始HTML骨架,真实数据藏在后续API调用中。410 收藏 -
 构建Python知识图谱需先确定知识范围与粒度,再提取知识点及其关系,接着使用工具表达为图结构,并持续迭代更新。具体步骤如下:1.确定知识范围和粒度:根据目标用户明确涵盖内容(如语法、标准库、第三方库等),并划分初级到应用层的层次;2.提取知识点与关系:识别实体(函数、模块、类等)及关系(属于、调用、继承等),可通过手动整理、NLP自动抽取或AST代码解析实现;3.使用图数据库或可视化工具表达:可选用Neo4j存储查询,Graphviz或Cytoscape.js进行可视化展示;4.不断迭代和扩展:定期更新410 收藏
构建Python知识图谱需先确定知识范围与粒度,再提取知识点及其关系,接着使用工具表达为图结构,并持续迭代更新。具体步骤如下:1.确定知识范围和粒度:根据目标用户明确涵盖内容(如语法、标准库、第三方库等),并划分初级到应用层的层次;2.提取知识点与关系:识别实体(函数、模块、类等)及关系(属于、调用、继承等),可通过手动整理、NLP自动抽取或AST代码解析实现;3.使用图数据库或可视化工具表达:可选用Neo4j存储查询,Graphviz或Cytoscape.js进行可视化展示;4.不断迭代和扩展:定期更新410 收藏 -
 当随机森林等模型基于StandardScaler标准化后的数据训练时,PartialDependenceDisplay默认显示缩放后的x轴值;本文介绍如何通过反向变换刻度标签,使PDP横轴回归原始业务单位,兼顾可解释性与技术正确性。410 收藏
当随机森林等模型基于StandardScaler标准化后的数据训练时,PartialDependenceDisplay默认显示缩放后的x轴值;本文介绍如何通过反向变换刻度标签,使PDP横轴回归原始业务单位,兼顾可解释性与技术正确性。410 收藏 -
 必须用@transaction.atomic当一组数据库操作需原子性执行,任一失败则全部回滚;它确保数据一致性,避免脏数据,适用于视图或管理命令,不可用于模型方法或异步视图。410 收藏
必须用@transaction.atomic当一组数据库操作需原子性执行,任一失败则全部回滚;它确保数据一致性,避免脏数据,适用于视图或管理命令,不可用于模型方法或异步视图。410 收藏 -
 ModelFormis_valid()返回False但errors为空,通常因表单未绑定数据;需检查是否传入request.POST、enctype、non_field_errors、字段是否在fields中、模型与数据库约束是否一致。410 收藏
ModelFormis_valid()返回False但errors为空,通常因表单未绑定数据;需检查是否传入request.POST、enctype、non_field_errors、字段是否在fields中、模型与数据库约束是否一致。410 收藏 -
 PCA适合解释性高、线性结构明显、大规模数据场景;t-SNE仅用于可视化探索,不可用于建模或距离计算,因其输出无几何距离意义、结果不可复现且对异常值敏感。410 收藏
PCA适合解释性高、线性结构明显、大规模数据场景;t-SNE仅用于可视化探索,不可用于建模或距离计算,因其输出无几何距离意义、结果不可复现且对异常值敏感。410 收藏 -
 本文介绍使用python-docx库通过检测段落中的分页符来准确计算Word文档页数的方法,避免依赖不稳定的节(section)计数或页脚页码解析。409 收藏
本文介绍使用python-docx库通过检测段落中的分页符来准确计算Word文档页数的方法,避免依赖不稳定的节(section)计数或页脚页码解析。409 收藏 -
 cProfile可快速定位慢函数,核心看tottime字段;用python-mcProfile启动或代码中嵌入Profile()控制启停,配合pstats排序分析,但无法检测I/O、C扩展及多线程耗时。409 收藏
cProfile可快速定位慢函数,核心看tottime字段;用python-mcProfile启动或代码中嵌入Profile()控制启停,配合pstats排序分析,但无法检测I/O、C扩展及多线程耗时。409 收藏 -
 M系列芯片上TensorFlow默认仅用CPU,需同时满足macOS≥12.3、安装匹配版本的tensorflow-macos与tensorflow-metal、启用GPU内存增长,并避免PyTorchMPS兼容性陷阱。409 收藏
M系列芯片上TensorFlow默认仅用CPU,需同时满足macOS≥12.3、安装匹配版本的tensorflow-macos与tensorflow-metal、启用GPU内存增长,并避免PyTorchMPS兼容性陷阱。409 收藏 -
 Python私有方法能直接调用,但需通过改写后的名称如_ClassName__method_name(),这违背封装原则,易导致维护困难、测试脆弱和设计缺陷。409 收藏
Python私有方法能直接调用,但需通过改写后的名称如_ClassName__method_name(),这违背封装原则,易导致维护困难、测试脆弱和设计缺陷。409 收藏