-

最稳妥方式是直接调用difflib.unified_diff,需传入带换行符的行列表和非空字符串文件名;避免Differ、注意编码与换行符统一、大文件宜用流式处理或替代库。
-

django-axes必须添加AxesMiddleware到MIDDLEWARE且置于AuthenticationMiddleware之后、CommonMiddleware之前,否则无法拦截登录请求;需配置INSTALLED_APPS、数据库迁移及关键参数如AXES_FAILURE_LIMIT和AXES_LOCK_OUT_BY_COMBINATION_USER_AND_IP。
-

asyncio.gather()需设return_exceptions=True才能继续执行并收集全部结果,此时异常对象会作为列表元素返回,需用isinstance(r,BaseException)判别,结果顺序与输入严格一致。
-

Python3.7+中dict已保证插入顺序,按键排序应直接用{k:d[k]forkinsorted(d)},无需OrderedDict;仅当需move_to_end()、popitem(last=False)或严格顺序相等性时才用OrderedDict。
-

Python文件操作必须进行精准异常处理:FileNotFoundError、PermissionError等需分类捕获,配合with语句、路径预检和日志记录,保障程序健壮性与用户体验。
-

Python字典键必须是可哈希类型,即对象生命周期内哈希值不变且实现__hash__()和__eq__()方法;常见可哈希类型包括int、str、tuple(元素全可哈希)、frozenset、None及合规自定义类;list、dict、set等不可变性或未实现哈希协议的类型不可用作键。
-

本文介绍如何使用Pandas的分类索引与外连接(outermerge)机制,强制补全所有预定义分箱区间(如(0,2],(2,4]等),将无覆盖数据的空bins统一赋值为0,确保热图横轴bins数量固定、位置对齐,避免因数据稀疏导致的可视化断层。
-

混合精度训练(AMP)与梯度压缩(如Top-K)必须错开执行:先scaler.unscale_()恢复FP32梯度,再压缩,否则缩放会扭曲梯度相对大小、破坏稀疏性选择逻辑;BN层梯度需跳过,且NCCL不支持稀疏通信,需改用sign+误差反馈等方案。
-

VSCode默认不调试子线程,需在launch.json中设置"subProcess":true和"justMyCode":false才能使threading.Thread中的断点生效。
-

根本原因是Python安装路径未添加到PATH环境变量,导致CMD无法定位python.exe;需在用户级PATH中添加精确安装目录(如C:\Users\Alice\AppData\Local\Programs\Python\Python312),重启CMD后用wherepython和python--version验证。
-

异步代码调试失灵的根本原因是协程未被事件循环调度,breakpoint()在未await的协程中不生效;需启用PYTHONASYNCIODEBUG=1捕获静默错误,并在VSCode中设"justMyCode":false以跟踪await调度。
-

使用np.memmap时,result[:]=a[:]-b[:]会意外创建完整中间数组导致OOM;应改用支持out=参数的ufunc(如np.subtract)直接写入磁盘映射内存,避免RAM缓存膨胀。
-

最安全直观的方式是对单列用df[col_name].apply(func);df.apply(func,axis=1)是按行操作而非按列,易导致报错或结果错误;axis=0(默认)才按列处理,但需函数适配Series输入。
-
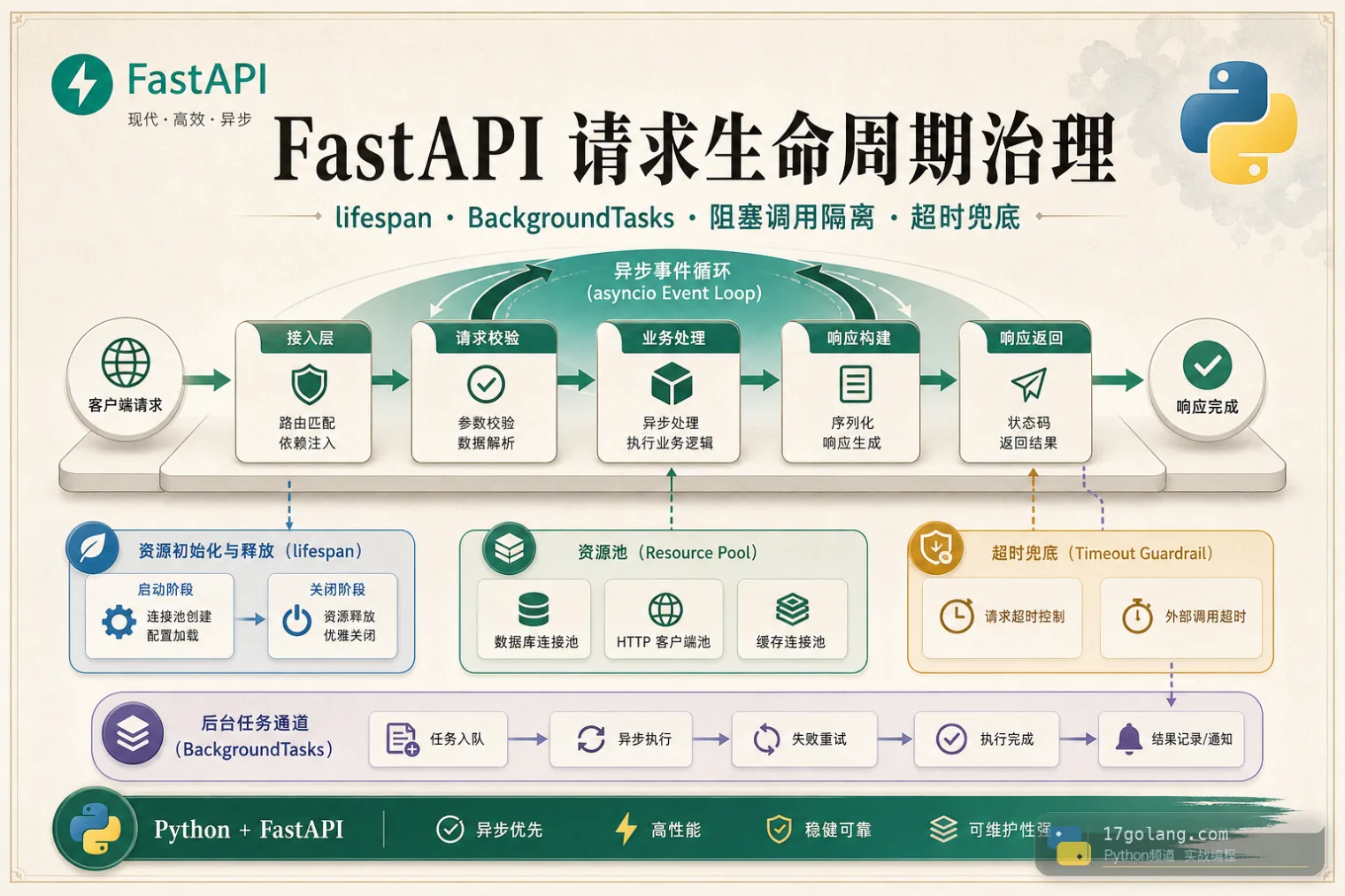
从 Python FastAPI 线上慢请求和后台任务丢失入手,讲清 lifespan 资源管理、阻塞调用隔离、BackgroundTasks 边界、超时和上线检查。
-

query()方法返回的是惰性求值的可迭代对象,即Query实例,非原生生成器或列表;遍历、list()、first()等操作才触发SQL执行,多次遍历会重复查询。