python教程技术文章
-
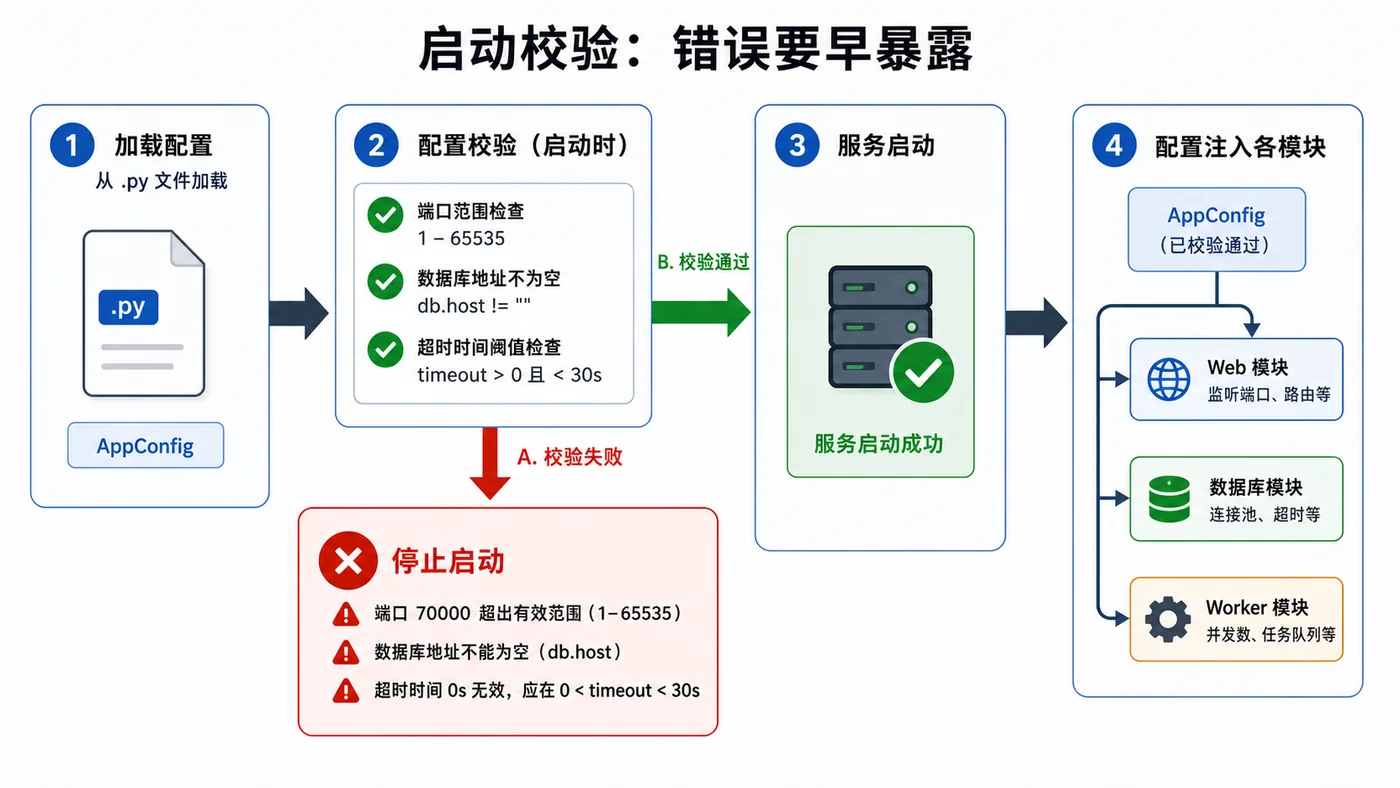 本文用标准库 dataclass 写一套轻量配置加载方案,演示默认值、环境变量覆盖、类型转换和启动校验,避免服务上线后才发现端口、数据库地址或超时参数写错。131 收藏
本文用标准库 dataclass 写一套轻量配置加载方案,演示默认值、环境变量覆盖、类型转换和启动校验,避免服务上线后才发现端口、数据库地址或超时参数写错。131 收藏 -
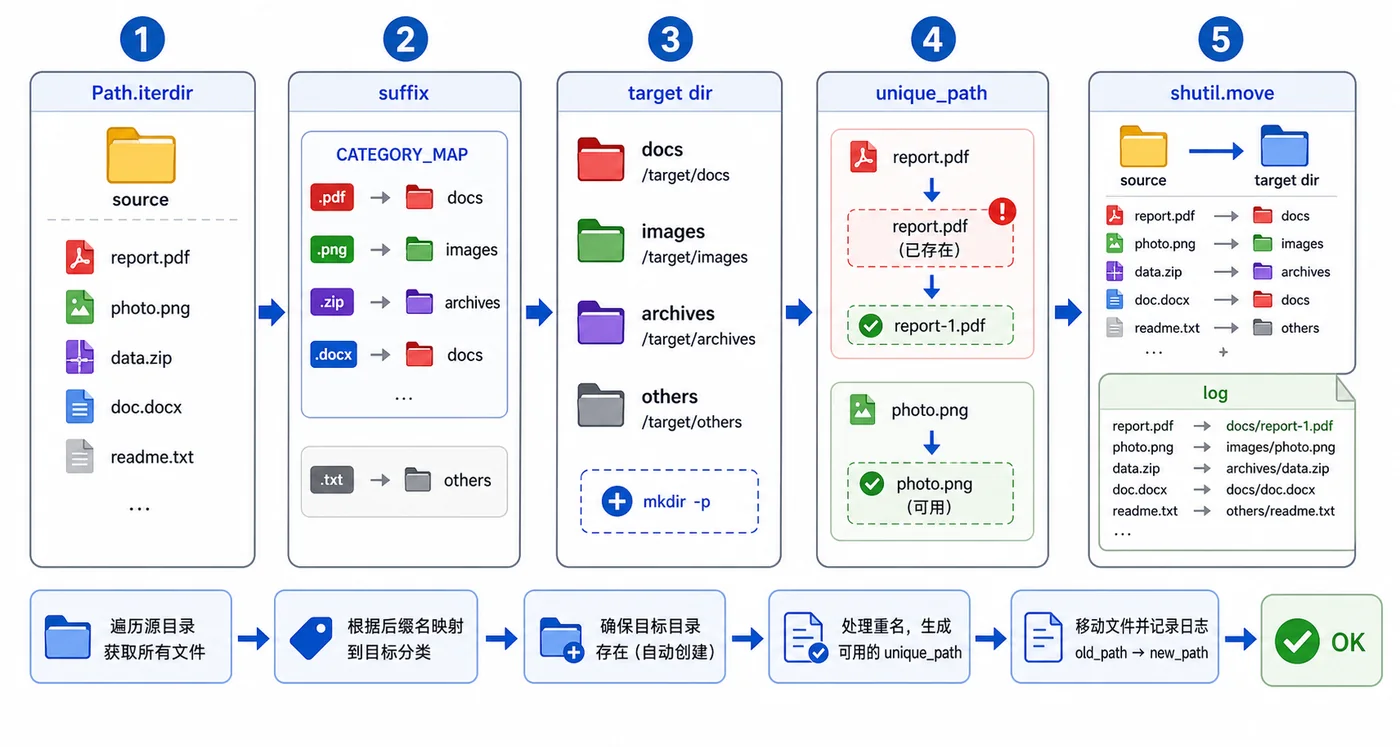 用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。166 收藏
用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。166 收藏 -
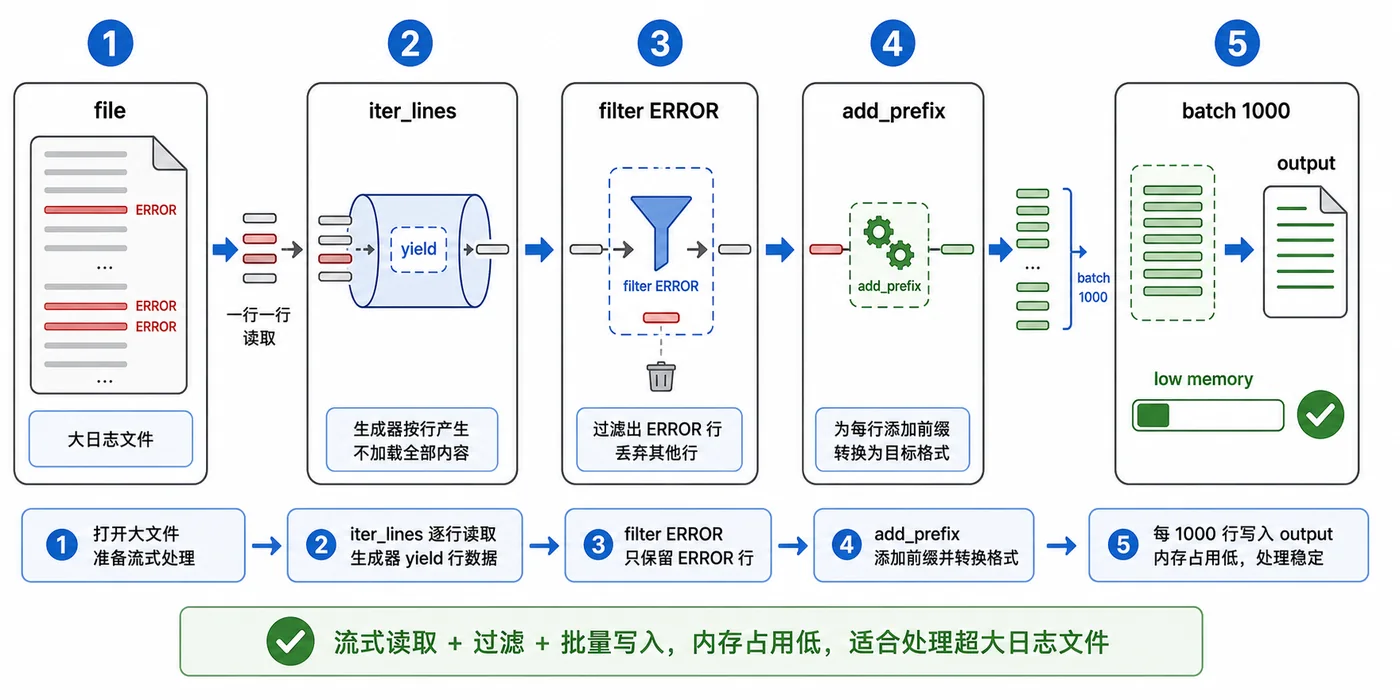 用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。311 收藏
用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。311 收藏 -
文章 · python教程 | 1个月前 | 日志 · 链路追踪 · Python教程 · contextvars · Python logging contextvars 日志追踪 trace_id 异步上下文
 通过一个接口请求日志案例,演示如何用 contextvars 保存 trace_id,并通过 logging Filter 自动写入每条日志,适合同步和异步 Python 项目排查问题。370 收藏
通过一个接口请求日志案例,演示如何用 contextvars 保存 trace_id,并通过 logging Filter 自动写入每条日志,适合同步和异步 Python 项目排查问题。370 收藏 -
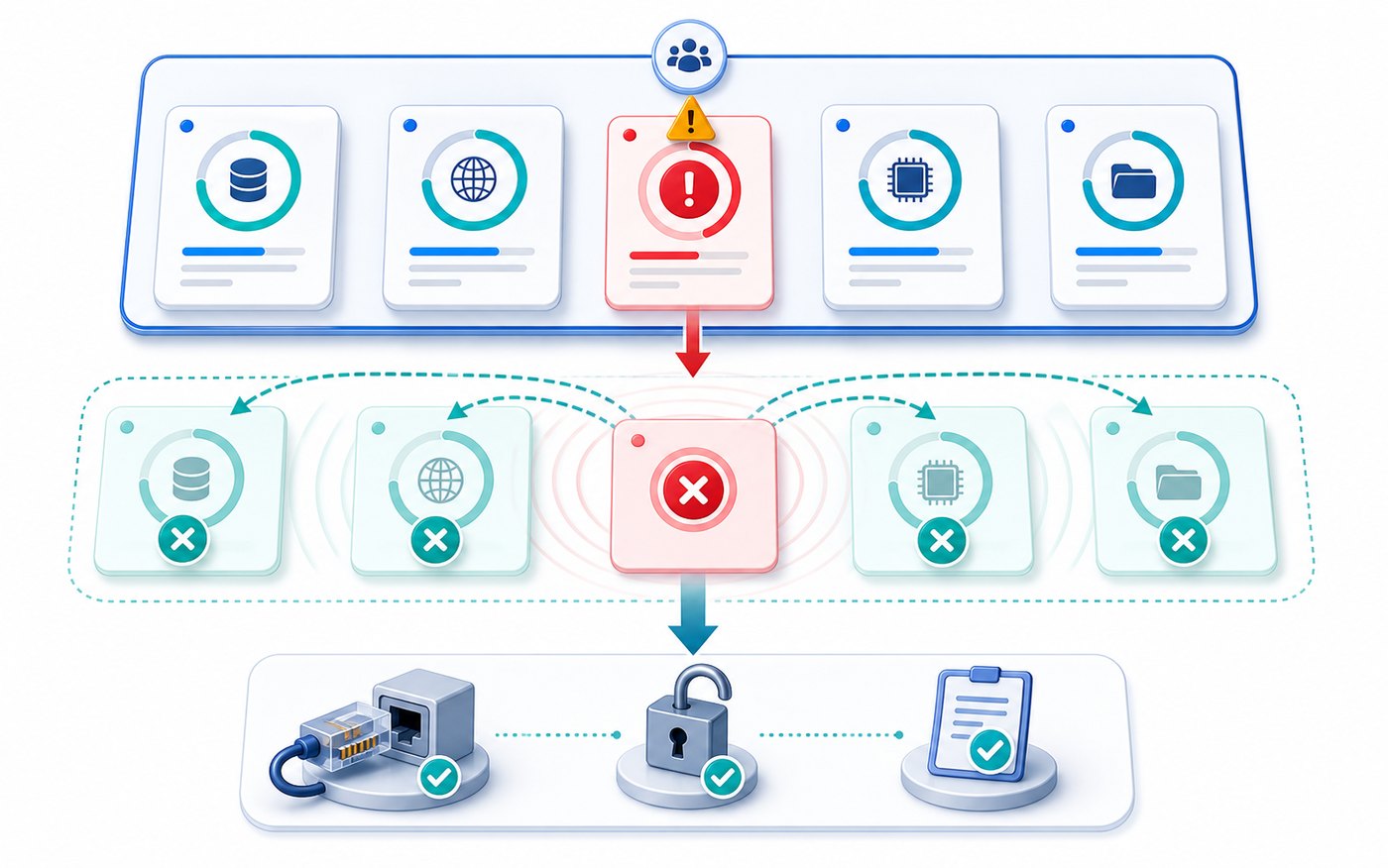 通过一个异步接口聚合案例,演示 asyncio.timeout、wait_for、TaskGroup、shield 和取消传播的用法,帮助 Python 项目把慢任务、半完成状态和资源清理管住。457 收藏
通过一个异步接口聚合案例,演示 asyncio.timeout、wait_for、TaskGroup、shield 和取消传播的用法,帮助 Python 项目把慢任务、半完成状态和资源清理管住。457 收藏 -
 通过外部 API 调用场景,演示 Python requests 如何设置 connect/read 超时、复用 Session 连接池、配置重试策略,并记录日志定位慢请求。105 收藏
通过外部 API 调用场景,演示 Python requests 如何设置 connect/read 超时、复用 Session 连接池、配置重试策略,并记录日志定位慢请求。105 收藏 -
文章 · python教程 | 1个月前 | 异步编程 · 生产实践 · 后端工程 · Python教程 · Celery · 任务队列 · Python 故障排查 任务队列 异步任务 幂等 生产实践 Celery 5.4 retry_backoff acks_late
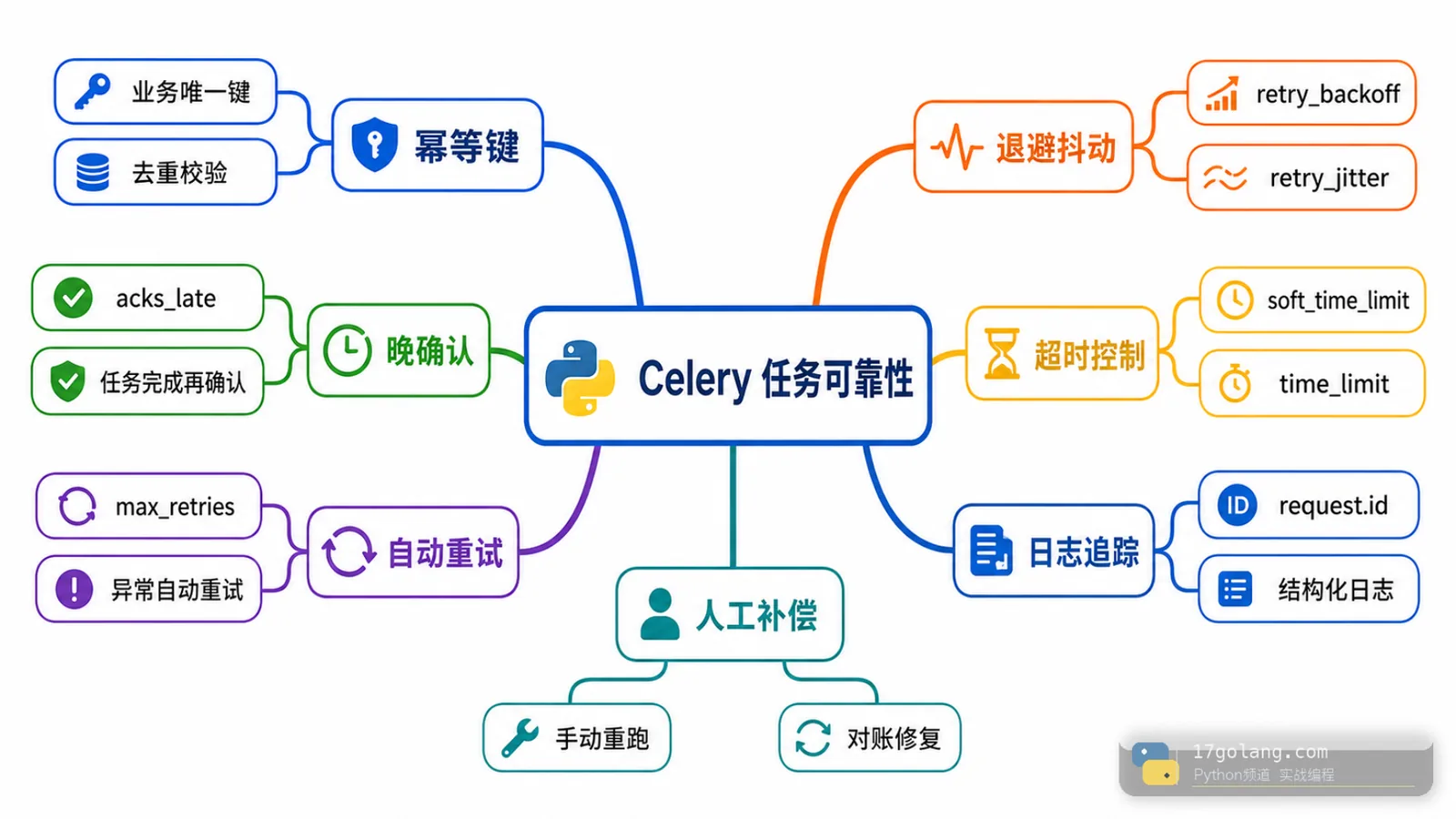 从 Python Celery 任务重复执行事故入手,实战讲解业务幂等键、acks_late、自动重试、指数退避、超时控制和上线观测。340 收藏
从 Python Celery 任务重复执行事故入手,实战讲解业务幂等键、acks_late、自动重试、指数退避、超时控制和上线观测。340 收藏 -
文章 · python教程 | 1个月前 | 工程化 · 性能优化 · 内存分析 · 故障排查 · 生产实践 · Python教程 · Python 故障排查 内存泄漏 rss 性能优化 GC tracemalloc 生产实践 snapshot diff
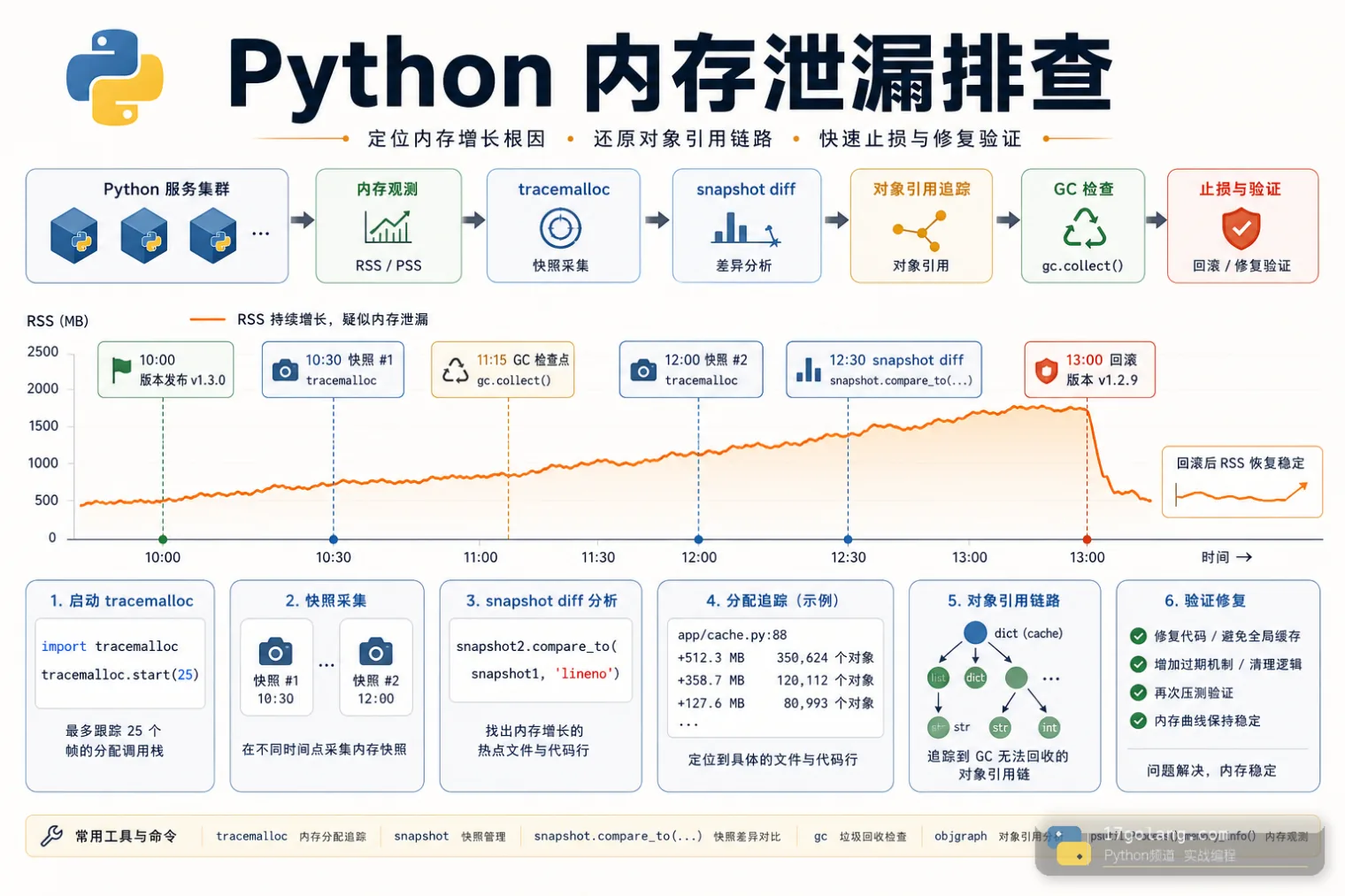 从 Python 服务 RSS 持续增长事故入手,实战讲解 tracemalloc 快照 diff、gc 引用检查、缓存失控定位和上线回归。230 收藏
从 Python 服务 RSS 持续增长事故入手,实战讲解 tracemalloc 快照 diff、gc 引用检查、缓存失控定位和上线回归。230 收藏 -
文章 · python教程 | 1个月前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志
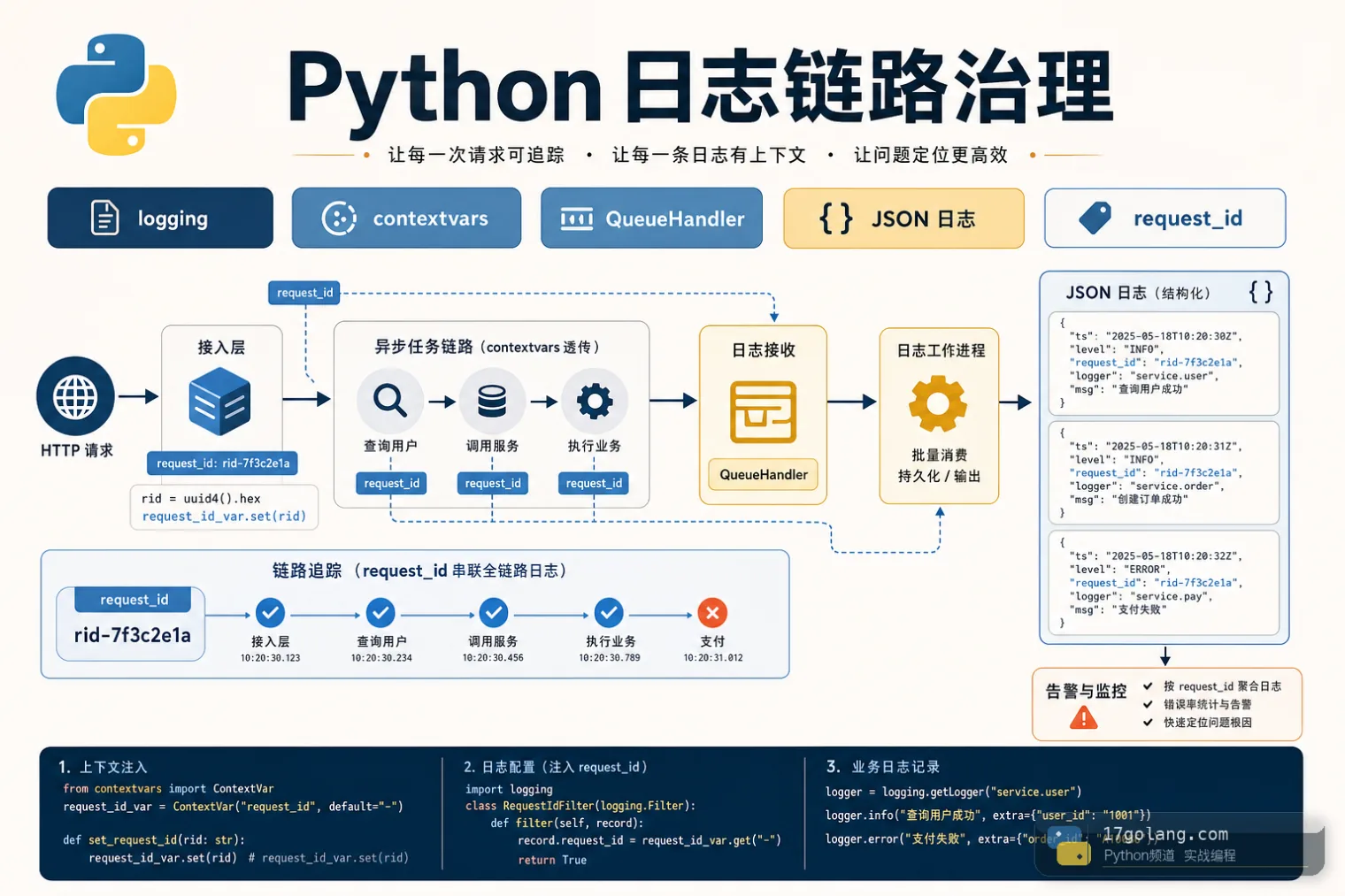 从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。427 收藏
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。427 收藏 -
文章 · python教程 | 1个月前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。189 收藏
-
文章 · python教程 | 1个月前 | 依赖管理 · 工程化 · CI · 生产实践 · Python教程 · 打包发布 · Python build 依赖管理 twine wheel 打包发布 pyproject.toml dependency-groups pylock.toml sdist
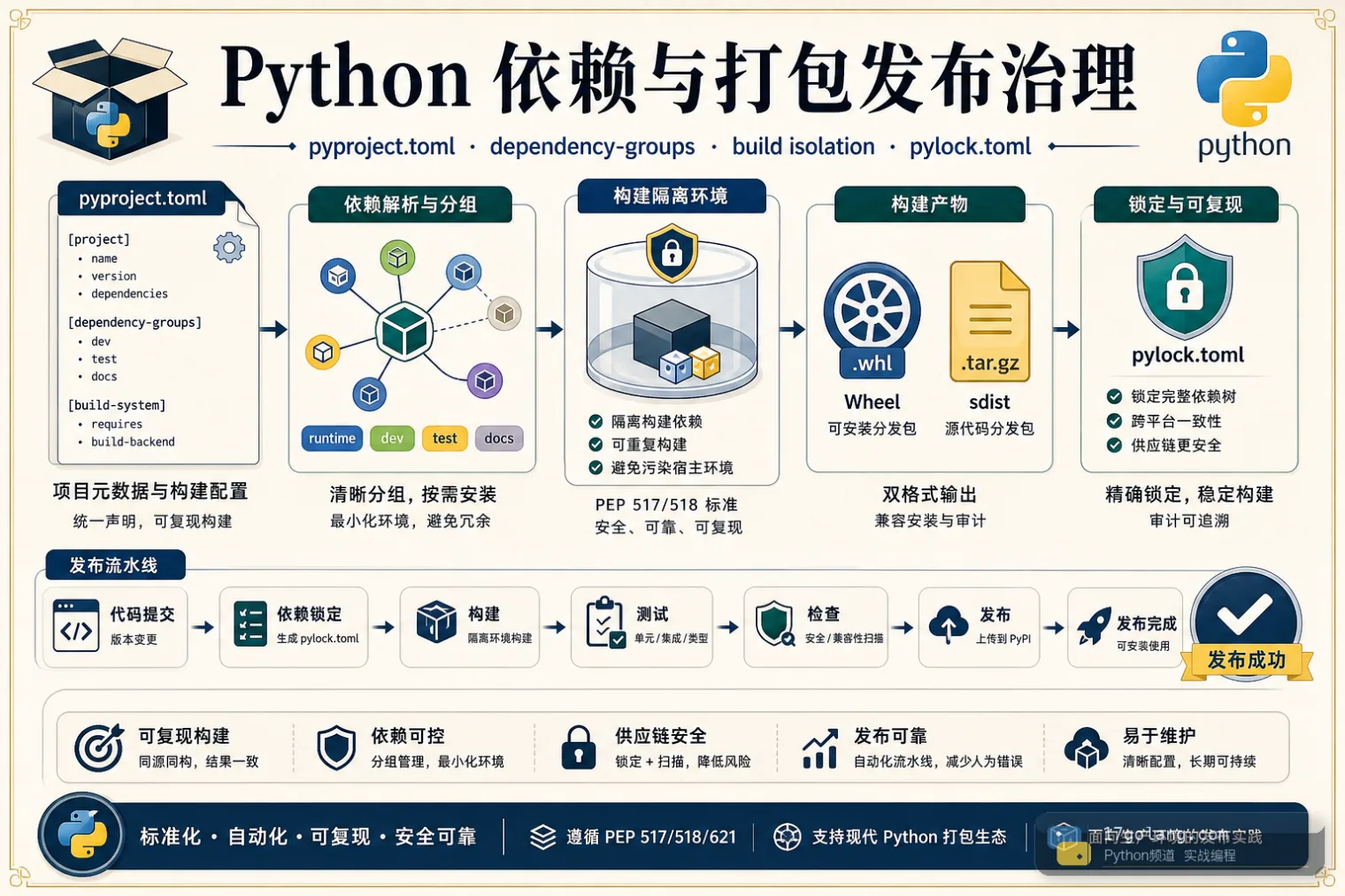 从 Python 内部包发布事故入手,讲清 pyproject.toml、dependency-groups、构建隔离、wheel/sdist 检查、锁文件和私有源 token 治理。479 收藏
从 Python 内部包发布事故入手,讲清 pyproject.toml、dependency-groups、构建隔离、wheel/sdist 检查、锁文件和私有源 token 治理。479 收藏 -
文章 · python教程 | 1个月前 | WEB开发 · 工程化 · 配置管理 · flask · 生产实践 · Python教程 · Python Flask G 配置管理 请求上下文 应用上下文 生产实践 current_app teardown app factory
 从 Python Flask 生产连接泄漏和上下文错误入手,讲清 app factory、配置加载、g 请求内资源缓存、teardown 清理和后台任务边界。257 收藏
从 Python Flask 生产连接泄漏和上下文错误入手,讲清 app factory、配置加载、g 请求内资源缓存、teardown 清理和后台任务边界。257 收藏 -
文章 · python教程 | 1个月前 | ORM · Django · 异步编程 · 生产实践 · Python教程 · 后端开发 · Python Django 性能优化 orm 事务 ASGI 生产实践 async view sync_to_async
 从 Python Django async view 线上改造入手,讲清异步视图、同步 ORM 边界、sync_to_async、事务收口和上线检查。310 收藏
从 Python Django async view 线上改造入手,讲清异步视图、同步 ORM 边界、sync_to_async、事务收口和上线检查。310 收藏 -
文章 · python教程 | 1个月前 | 性能优化 · 异步编程 · fastapi · 生产实践 · Python教程 · API服务 · Python API服务 FastAPI asyncio httpx 生产实践 lifespan BackgroundTasks run_in_threadpool
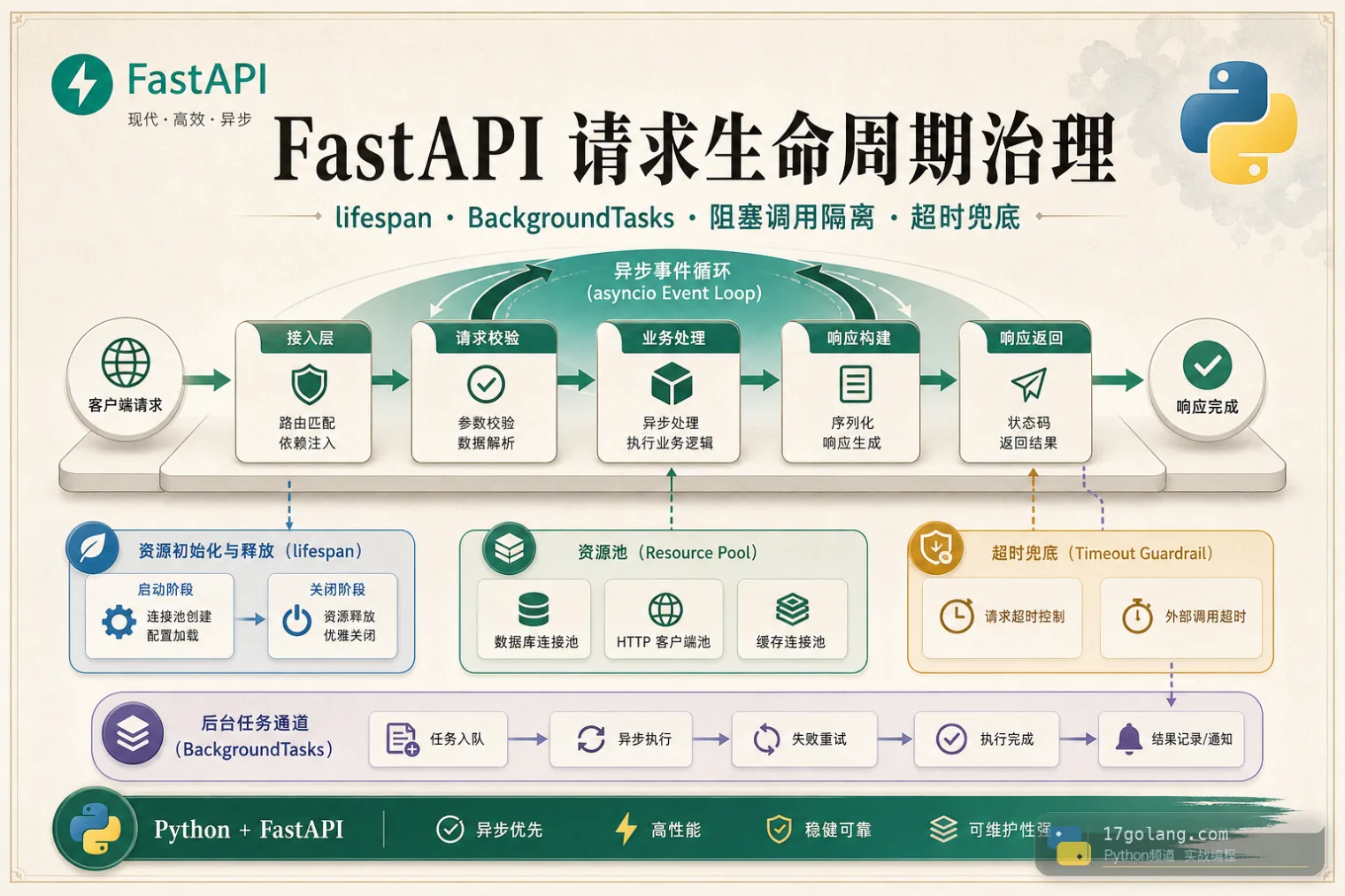 从 Python FastAPI 线上慢请求和后台任务丢失入手,讲清 lifespan 资源管理、阻塞调用隔离、BackgroundTasks 边界、超时和上线检查。411 收藏
从 Python FastAPI 线上慢请求和后台任务丢失入手,讲清 lifespan 资源管理、阻塞调用隔离、BackgroundTasks 边界、超时和上线检查。411 收藏 -
文章 · python教程 | 1个月前 | 工程化 · 自动化测试 · pytest · CI · 生产实践 · Python教程 · Python CI pytest fixture tmp_path monkeypatch pytest-xdist 测试稳定性
 从 Python 项目 CI 偶发失败入手,讲清 pytest fixture 共享状态、tmp_path 文件隔离、monkeypatch 自动回滚和 xdist 并发验证的实战治理方法。303 收藏
从 Python 项目 CI 偶发失败入手,讲清 pytest fixture 共享状态、tmp_path 文件隔离、monkeypatch 自动回滚和 xdist 并发验证的实战治理方法。303 收藏