python教程技术文章
-
文章 · python教程 | 1个月前 | sqlalchemy · 异步编程 · fastapi · 生产实践 · Python教程 · Python 连接池 FastAPI sqlalchemy asyncio AsyncSession
 从 FastAPI 生产接口连接池等待场景讲清 SQLAlchemy AsyncSession 并发使用、事务边界、连接池参数和上线检查。340 收藏
从 FastAPI 生产接口连接池等待场景讲清 SQLAlchemy AsyncSession 并发使用、事务边界、连接池参数和上线检查。340 收藏 -
文章 · python教程 | 1个月前 | 性能优化 · fastapi · 生产实践 · Python教程 · Pydantic · Python 性能优化 FastAPI Pydantic v2 TypeAdapter validate_json
 从 FastAPI 生产接口 P95 升高场景讲清 Pydantic v2 TypeAdapter 复用、validate_json、strict、FailFast 和压测验证。342 收藏
从 FastAPI 生产接口 P95 升高场景讲清 Pydantic v2 TypeAdapter 复用、validate_json、strict、FailFast 和压测验证。342 收藏 -
文章 · python教程 | 1个月前 | 性能优化 · gil · 生产实践 · Python教程 · CPython · Python 性能优化 线程安全 gil CPython free-threaded
 从生产迁移角度讲清 Python free-threaded CPython、禁用 GIL、依赖兼容、线程安全、压测基线和灰度回滚。381 收藏
从生产迁移角度讲清 Python free-threaded CPython、禁用 GIL、依赖兼容、线程安全、压测基线和灰度回滚。381 收藏 -
文章 · python教程 | 1个月前 | 异步编程 · fastapi · 后端架构 · Python教程 · asyncio · Python 异步编程 FastAPI asyncio TaskGroup 生产实践
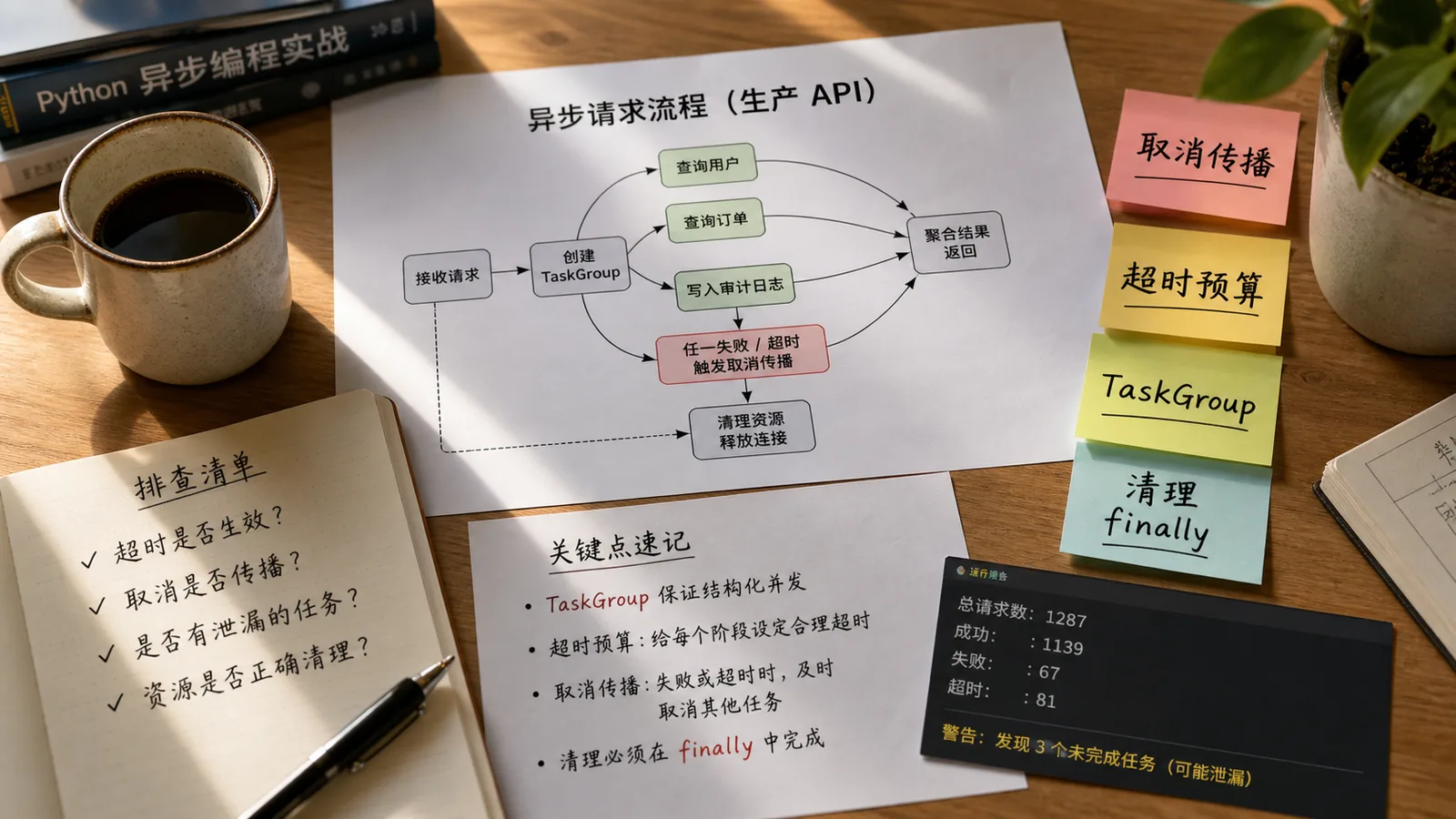 从 FastAPI 生产接口超时场景讲透 Python asyncio TaskGroup、timeout、取消传播、ExceptionGroup 和 finally 资源清理。496 收藏
从 FastAPI 生产接口超时场景讲透 Python asyncio TaskGroup、timeout、取消传播、ExceptionGroup 和 finally 资源清理。496 收藏 -
 手写数字识别需注重数据预处理、模型结构、训练配置和评估调试四大细节:归一化至[0,1]并增加通道维;采用轻量CNN(两卷积块+Flatten+Dense);用Adam优化器、sparse_categorical_crossentropy损失、batch_size=32/64;测试准确率应达98.5%+,否则检查标签编码、预测方式及训练轮次。447 收藏
手写数字识别需注重数据预处理、模型结构、训练配置和评估调试四大细节:归一化至[0,1]并增加通道维;采用轻量CNN(两卷积块+Flatten+Dense);用Adam优化器、sparse_categorical_crossentropy损失、batch_size=32/64;测试准确率应达98.5%+,否则检查标签编码、预测方式及训练轮次。447 收藏 -
 递归函数测试最常漏掉的三个边界是0、1、负值;出错常因边界未处理,如factorial(n)未处理n==0或n<0导致栈溢出或错误结果。189 收藏
递归函数测试最常漏掉的三个边界是0、1、负值;出错常因边界未处理,如factorial(n)未处理n==0或n<0导致栈溢出或错误结果。189 收藏 -
 Python结合Selenium无头模式实现网页截图的核心步骤是:1.安装selenium库并下载对应浏览器的WebDriver;2.导入webdriver和Options模块;3.创建ChromeOptions对象并添加--headless、--disable-gpu、--window-size等参数;4.实例化webdriver.Chrome并传入配置;5.使用driver.get访问目标URL;6.等待页面加载完成;7.调用driver.save_screenshot保存截图;8.最后使用drive462 收藏
Python结合Selenium无头模式实现网页截图的核心步骤是:1.安装selenium库并下载对应浏览器的WebDriver;2.导入webdriver和Options模块;3.创建ChromeOptions对象并添加--headless、--disable-gpu、--window-size等参数;4.实例化webdriver.Chrome并传入配置;5.使用driver.get访问目标URL;6.等待页面加载完成;7.调用driver.save_screenshot保存截图;8.最后使用drive462 收藏 -
 猜数字游戏是Python入门的绝佳实践,它融合了随机数生成、用户交互、条件判断和循环控制等核心编程概念。通过构建这个游戏,初学者能直观理解代码如何与用户互动,并在解决输入验证、类型转换等问题的过程中加深对编程逻辑和数据类型的掌握。加入次数限制、自定义范围和再玩一次等功能可提升趣味性和挑战性,而良好的代码结构、变量命名及异常处理则有助于培养规范的编程习惯。这个小游戏不仅是语法练习,更是编程思维的启蒙训练。318 收藏
猜数字游戏是Python入门的绝佳实践,它融合了随机数生成、用户交互、条件判断和循环控制等核心编程概念。通过构建这个游戏,初学者能直观理解代码如何与用户互动,并在解决输入验证、类型转换等问题的过程中加深对编程逻辑和数据类型的掌握。加入次数限制、自定义范围和再玩一次等功能可提升趣味性和挑战性,而良好的代码结构、变量命名及异常处理则有助于培养规范的编程习惯。这个小游戏不仅是语法练习,更是编程思维的启蒙训练。318 收藏 -
 RLock允许同一线程多次acquire,Lock不行;RLock内部维护线程ID和计数器,支持递归调用,但不可用于跨线程等待,也不能与Lock混用acquire/release。387 收藏
RLock允许同一线程多次acquire,Lock不行;RLock内部维护线程ID和计数器,支持递归调用,但不可用于跨线程等待,也不能与Lock混用acquire/release。387 收藏 -
 直接选择Python3.10及以上版本最合适,因其性能更强、语法更现代、错误提示更清晰;Python2已停止维护,资源不兼容且存在安全隐患;推荐安装python.org提供的最新稳定版如Python3.12,并通过python--version验证版本。437 收藏
直接选择Python3.10及以上版本最合适,因其性能更强、语法更现代、错误提示更清晰;Python2已停止维护,资源不兼容且存在安全隐患;推荐安装python.org提供的最新稳定版如Python3.12,并通过python--version验证版本。437 收藏 -
 strip()仅删除字符串首尾属于指定字符集的字符,不按子串匹配;removeprefix/removesuffix则精确删除固定前缀或后缀,Python3.9+引入,语义明确、安全可靠。252 收藏
strip()仅删除字符串首尾属于指定字符集的字符,不按子串匹配;removeprefix/removesuffix则精确删除固定前缀或后缀,Python3.9+引入,语义明确、安全可靠。252 收藏 -
 不安全。Flask的session虽支持字典操作,但仅防篡改不加密,依赖SECRET_KEY签名Cookie;未设密钥则静默失效;应优先用session.get()防KeyError,并避免存敏感数据。244 收藏
不安全。Flask的session虽支持字典操作,但仅防篡改不加密,依赖SECRET_KEY签名Cookie;未设密钥则静默失效;应优先用session.get()防KeyError,并避免存敏感数据。244 收藏 -
 Python3.12安装后cmd报“不是内部或外部命令”主因是PATH未正确配置,安装时必须勾选“Addpython.exetoPATH”,否则需手动添加安装目录及Scripts路径到系统环境变量。119 收藏
Python3.12安装后cmd报“不是内部或外部命令”主因是PATH未正确配置,安装时必须勾选“Addpython.exetoPATH”,否则需手动添加安装目录及Scripts路径到系统环境变量。119 收藏 -
 async-lru能直接装饰asyncdef函数,但必须用@alru_cache()(带括号),否则装饰器未生效;它基于asyncio.Lock保证并发安全,缓存键由可哈希参数生成,不支持TTL、不可哈希类型或session实例传参。261 收藏
async-lru能直接装饰asyncdef函数,但必须用@alru_cache()(带括号),否则装饰器未生效;它基于asyncio.Lock保证并发安全,缓存键由可哈希参数生成,不支持TTL、不可哈希类型或session实例传参。261 收藏 -
 本文详解如何在Python中使用glob模块编写准确的通配符模式,匹配形如123_beta_faces.nii.gz或042_beta_faces_up.nii.gz的文件路径,避免过度匹配,并给出可直接运行的代码示例与关键注意事项。本文详解如何在Python中使用`glob`模块编写准确的通配符模式,匹配形如`123_beta_faces.nii.gz`或`042_beta_faces_up.nii.gz`的文件路径,避免267 收藏
本文详解如何在Python中使用glob模块编写准确的通配符模式,匹配形如123_beta_faces.nii.gz或042_beta_faces_up.nii.gz的文件路径,避免过度匹配,并给出可直接运行的代码示例与关键注意事项。本文详解如何在Python中使用`glob`模块编写准确的通配符模式,匹配形如`123_beta_faces.nii.gz`或`042_beta_faces_up.nii.gz`的文件路径,避免267 收藏