-

成都东凯芯半导体材料有限公司(简称“东凯芯半导体”)近期成功完成A轮融资,投资方为诚信创投。根据官方资料,东凯芯半导体是东材科技集团旗下的企业,成立于2023年5月,专注于高端光刻胶材料的研发。公司在光刻胶材料的合成与纯化方面具备一定的技术实力,并申请了多项专利,例如“一种(4-叔丁基苯基)二苯基氯化硫鎓盐的合成工艺”和“1-(4-烷氧基萘基)-1H-环锍鎓全氟丁基磺酸盐”等。今年1月,东材科技发布公告,称其控股子公司东凯芯半导体计划增资扩股并引入机构投资者。增资完成后,成都东凯芯的注册资
-
利用豆包AI生成明星表情包的步骤包括:1.选择热门明星或公众人物;2.通过工具库挑选图像处理功能;3.导入明星照片并利用AI生成表情包。豆包AI生成的表情包能吸引粉丝的原因是:1.快速反映热点事件;2.利用大数据分析用户喜好;3.传播性强;4.高质量和多样性。
-
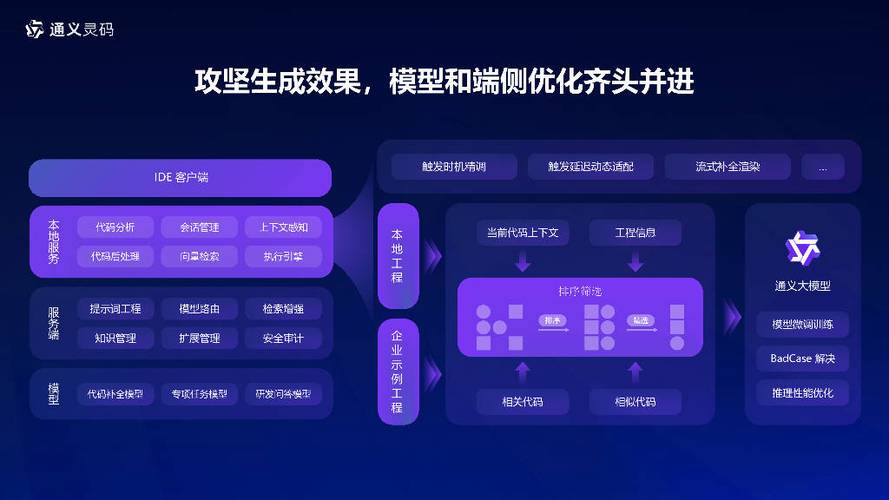
如何开始使用通灵义码?首先下载并安装软件,然后启动程序并注册账号。注册后探索基本功能,如创建新项目和导入代码库。通灵义码的高级功能包括机器学习模型的训练和部署。优化工作流程需熟悉自动化脚本和与其他工具集成。实际应用案例如数据分析和软件测试自动化。遇到问题时,查阅官方文档或社区论坛寻求帮助。
-

DeepSeek与飞书可以通过API集成或第三方插件关联,提升团队协作智能化。1.API集成需注册开发者账号,获取API密钥,并在飞书平台编写自定义应用嵌入DeepSeek的API。2.DeepSeek可分析团队沟通模式,优化工作流程,智能分配任务。3.集成挑战包括API稳定性和数据隐私,需调试优化和设计安全机制。4.评估集成效果可通过工作效率、项目时间、成员满意度等维度进行定期评估。
-

想用豆包AI生成准确代码需具体描述功能、说明运行环境、指出所需库;1.明确功能如“自动整理桌面文件”而非模糊请求;2.提供系统和语言版本如Windows+Python3.10;3.指定模块如os和shutil;4.补充条件如异常处理或目录判断。遇到错误可复制报错信息并当前代码提问,要求解释原因及修改建议。学习编程技巧可通过追问完善逻辑,如批量重命名文件时问保留原名、防覆盖、加日期戳等。实战中还可让豆包AI添加注释和文档字符串提升代码可读性。关键在提问方式与逐步引导,使其更贴合需求。
-

DeepSeek的代码生成功能通过理解需求提升编程效率,但需清晰描述需求、提供上下文、多次迭代、善用片段、结合测试。处理复杂逻辑时应分解任务,优化可读性需指定风格、加注释、重构代码、使用有意义变量名,同时必须审查安全性,防止漏洞。
-

AIOverviews类产品存在隐私和数据安全风险,主要源于用户查询、模型生成内容等环节涉及个人信息流转。1.数据处理流程包括接收查询→调用模型推理→返回结果,过程中原始输入、中间数据和输出可能被记录或存储;2.平台若默认保存数据用于优化模型,将增加泄露风险;3.部分产品缓存生成内容且缺乏加密传输机制,可能在传输中被拦截;4.是否构成风险取决于平台是否明确数据流向并提供关闭选项;5.平台政策常见要点包括匿名化处理、限定保留周期、用户控制权及企业版加密支持;6.降低风险的方法包括避免输入敏感信息、启用隐私模
-

多模态AI在医疗领域的应用场景包括疾病诊断、个性化治疗、药物研发、智能辅助决策和远程医疗;接入方案需明确需求、评估数据、选择平台、考虑成本、关注合规并开展试点项目;合规要点涵盖数据隐私、数据安全、算法透明度、算法公平性、责任归属、患者知情权、持续监控制和伦理审查。
-

天眼查数据显示,杭州中欣晶圆半导体股份有限公司近日公开了名为“改善硅片边缘金属的方法”的专利信息,该专利的申请公布日期为2025年3月14日,申请号为CN119608644A。本发明提供了一种用于改善硅片边缘金属状况的方法,属于硅片加工技术领域。具体包括以下步骤:第一步:使用纯水对二手片盒进行喷淋清洗,持续时间为5分钟,纯水流量为25Lpm。第二步:将二手片盒置于含有盐酸的纯水浸泡槽中,浸泡时长为30分钟。第三步:再次使用纯水对二手片盒进行喷淋清洗,时间延长至10分钟,同时提高纯水流量至40Lpm。第四步
-
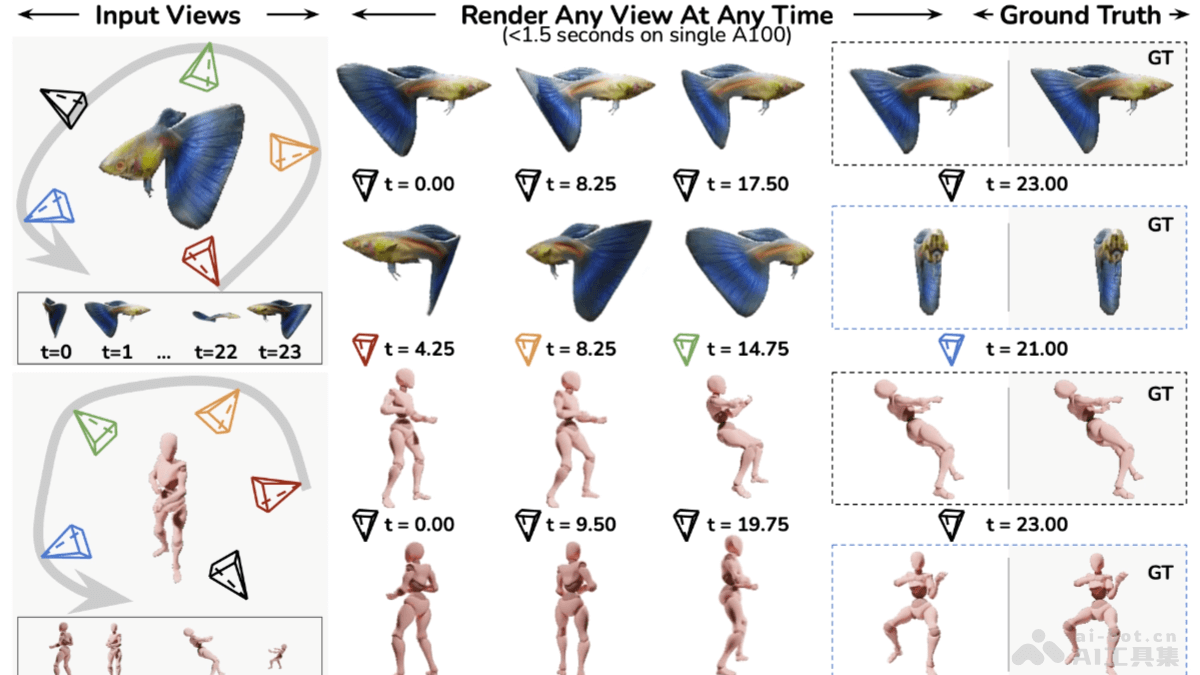
4D-LRM是什么4D-LRM(LargeSpace-TimeReconstructionModel)是由Adobe研究公司、密歇根大学等机构的研究人员共同开发的一种新型4D重建模型。该模型能够基于稀疏的输入视图和任意时间点,快速且高质量地重建出任意新视图和时间组合的动态场景。它采用基于Transformer的架构,用于预测每个像素的4D高斯原语,从而实现空间与时间的统一表示,展现出卓越的效率和强大的泛化能力。4D-LRM在多种相机设置下均表现出色,尤其是在交替使用规范视图和进行帧插值的情况下,能够
-

使用豆包AI写自动化测试脚本的关键在于明确需求并按步骤执行。1.明确测试页面和功能,如测试登录流程;2.告知使用的技术栈,如Python+Selenium或Node.js+Puppeteer;3.提供具体操作步骤,包括输入内容、点击按钮及验证行为;4.检查生成的代码是否需补充等待机制或处理干扰元素。只要描述清楚,豆包AI能快速生成可用框架,后续微调由人工完成即可。
-

Deepseek与Synthesia的结合通过自动化内容生成与视频制作大幅提升效率与质量。首先,Deepseek根据受众、时长与主题生成结构严谨、风格定制的文案脚本,实现秒级输出与快速迭代;其次,Synthesia将文本转化为带有自然表情、动作与唇形同步的虚拟数字人视频,省去拍摄与剪辑等繁琐流程;最终,在保证专业性与一致性的同时,使高质量视频内容生产更高效触手可及。
-

PerplexityAI虽非专门代码搜索引擎,但能通过语义理解和深度学习模型辅助编程。1.其代码搜索基于训练数据中的样例生成推荐代码,不依赖实时联网查询;2.它通过大量多语言训练理解语法结构及高级概念,并可指出错误、建议修改、支持多语言混合解析;3.高效使用方法包括明确指定语言、说明具体场景、提供上下文信息、要求带注释代码,以提升准确性与实用性。
-

PerplexityAI提供免费和付费版本,免费版适合轻度使用,提供基础搜索与问答功能、每日有限的高级功能调用及通用知识查询支持,但响应速度、并发数和API权限受限;1.Pro计划每月约20美元,提供更高请求配额、更快响应速度、访问复杂模型及商业内容生成权限;2.企业版支持团队协作、定制API、数据安全保护及专属技术支持,适用于市场调研、数据分析等专业场景。
-

设计模式是解决编程中常见问题的经验总结,它与OOP关系密切,因为OOP的封装、继承、多态等特性是实现这些模式的基础。例如,工厂模式用于灵活创建对象,观察者模式用于松耦合地协同多个对象。学习时常见误区包括为用模式而用模式、背下来却不会用。豆包AI可通过生活化类比、根据理解水平调整讲解方式、提供可运行代码片段、帮助识别适用场景等方式辅助学习。建议从项目中的重复逻辑入手,先写出能工作的代码再重构,并结合开源项目源码加深理解,最后要注重动手实践才能真正掌握设计模式。