人工智能技术文章
-
 近日,一项新研究发布于PNAS,再次刷新了神经网络的能力。这次神经网络被用来解决了高等数学题,而且还是麻省理工数学课程难度的数学题!在这项新研究中,研究团队证明了 OpenAI 的 Codex496 收藏
近日,一项新研究发布于PNAS,再次刷新了神经网络的能力。这次神经网络被用来解决了高等数学题,而且还是麻省理工数学课程难度的数学题!在这项新研究中,研究团队证明了 OpenAI 的 Codex496 收藏 -
 嘉宾:史树明撰稿:莫奇审校:云昭“大多数研究工作往往是围绕一个点展开,而点状的成果很难直接被用户所用。”腾讯 AI Lab 自然语言处理中心总监史树明说道。过去十余年间,人工496 收藏
嘉宾:史树明撰稿:莫奇审校:云昭“大多数研究工作往往是围绕一个点展开,而点状的成果很难直接被用户所用。”腾讯 AI Lab 自然语言处理中心总监史树明说道。过去十余年间,人工496 收藏 -
 自从 OpenAI 发布 ChatGPT 后,最近几个月聊天机器人热度不减。虽然 ChatGPT 功能强大,但 OpenAI 几乎不可能将其开源。不少人都在做开源方面的努力,比如前段时间 Meta 开源的 LLaMA。其是一系列模496 收藏
自从 OpenAI 发布 ChatGPT 后,最近几个月聊天机器人热度不减。虽然 ChatGPT 功能强大,但 OpenAI 几乎不可能将其开源。不少人都在做开源方面的努力,比如前段时间 Meta 开源的 LLaMA。其是一系列模496 收藏 -
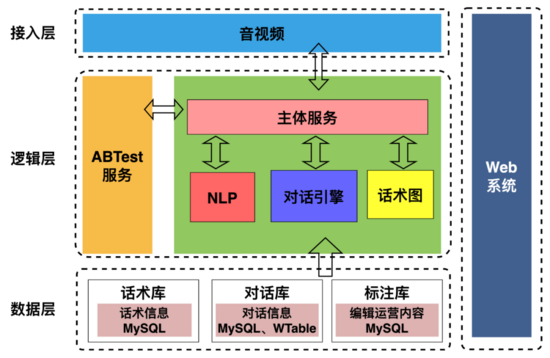 01 导读AI面试机器人通过利用灵犀智能语音语义平台的人机语音对话能力模拟招聘者与求职者进行多轮语音沟通,达到在线化面试的效果。本文详细描述了AI面试机器人的后端架构组成、对话引496 收藏
01 导读AI面试机器人通过利用灵犀智能语音语义平台的人机语音对话能力模拟招聘者与求职者进行多轮语音沟通,达到在线化面试的效果。本文详细描述了AI面试机器人的后端架构组成、对话引496 收藏 -
 岁末年初,ChatGPT火了。2022年11月下旬,由OpenAI推出的ChatGPT在网络引起了不小的轰动,短短一周时间便吸引了一百万用户在线试用,两个月时间用户直接破亿。可以说,ChatGPT是继AI音箱之后被炒496 收藏
岁末年初,ChatGPT火了。2022年11月下旬,由OpenAI推出的ChatGPT在网络引起了不小的轰动,短短一周时间便吸引了一百万用户在线试用,两个月时间用户直接破亿。可以说,ChatGPT是继AI音箱之后被炒496 收藏 -
 这两天,图灵奖得主Yann LeCun心态有些崩了。自从ChatGPT大火之后,微软凭着OpenAI腰板挺得很直。被啪啪打脸的谷歌,也不说什么「声誉风险」了。所有旗下的语言模型,无论是LaMDA,还是DeepMind的496 收藏
这两天,图灵奖得主Yann LeCun心态有些崩了。自从ChatGPT大火之后,微软凭着OpenAI腰板挺得很直。被啪啪打脸的谷歌,也不说什么「声誉风险」了。所有旗下的语言模型,无论是LaMDA,还是DeepMind的496 收藏 -
 近年来,围绕人工智能的风险争议一直广泛存在。特斯拉公司CEO埃隆·马斯克曾经公开警告,计算机系统最早可能在2029年时就会拥有人类智能,如果政府不对其进行监管和干预,该技术可能成496 收藏
近年来,围绕人工智能的风险争议一直广泛存在。特斯拉公司CEO埃隆·马斯克曾经公开警告,计算机系统最早可能在2029年时就会拥有人类智能,如果政府不对其进行监管和干预,该技术可能成496 收藏 -
 需注册RecraftAI账号方可使用全部功能:一、访问官网recraft.ai确认标识与登录按钮;二、点击“Signin”后选“Createaccount”;三、填有效邮箱、强密码并同意协议;四、查收验证邮件并点击链接完成验证;五、遇403错误需检查邮箱验证、API权限及Workspace角色;六、表单无响应时应清缓存、禁插件、换浏览器或净化字符。495 收藏
需注册RecraftAI账号方可使用全部功能:一、访问官网recraft.ai确认标识与登录按钮;二、点击“Signin”后选“Createaccount”;三、填有效邮箱、强密码并同意协议;四、查收验证邮件并点击链接完成验证;五、遇403错误需检查邮箱验证、API权限及Workspace角色;六、表单无响应时应清缓存、禁插件、换浏览器或净化字符。495 收藏 -
 要实现烟雾缭绕的仙境氛围,需优化提示词结构嵌入专业雾气描述符、选用适配的模型版本与参数组合、采用分阶段生成+后期雾层叠加法,或直接调用即梦内置“仙境雾霭”特效。495 收藏
要实现烟雾缭绕的仙境氛围,需优化提示词结构嵌入专业雾气描述符、选用适配的模型版本与参数组合、采用分阶段生成+后期雾层叠加法,或直接调用即梦内置“仙境雾霭”特效。495 收藏 -
 Qoder报“无法连接到本地服务”是因WindowsLoopback限制拦截localhost通信。可选四法:一、PowerShell执行CheckNetIsolation豁免;二、配置Lingma监听局域网IP;三、启用开发者模式;四、修改IDEJVM参数启用IPv4栈。495 收藏
Qoder报“无法连接到本地服务”是因WindowsLoopback限制拦截localhost通信。可选四法:一、PowerShell执行CheckNetIsolation豁免;二、配置Lingma监听局域网IP;三、启用开发者模式;四、修改IDEJVM参数启用IPv4栈。495 收藏 -
 可借助豆包App的AI写作、PDF提取重写、行业智能体、图文混排及多轮校验五大路径生成专业说明书:一用AI构建框架;二传PDF精准提取;三调专用智能体嵌入合规条款;四传图实现图文匹配;五经三次校验提升专业度。495 收藏
可借助豆包App的AI写作、PDF提取重写、行业智能体、图文混排及多轮校验五大路径生成专业说明书:一用AI构建框架;二传PDF精准提取;三调专用智能体嵌入合规条款;四传图实现图文匹配;五经三次校验提升专业度。495 收藏 -
 需验证Python≥3.8、NVIDIA驱动与CUDA匹配、无冲突PyTorch;用pip3--user安装SDK并配置PATH;通过环境变量设置API_KEY和GROUP_ID;运行chat示例验证连通性;根据HTTP状态码(401/403/超时)定位鉴权或网络问题。495 收藏
需验证Python≥3.8、NVIDIA驱动与CUDA匹配、无冲突PyTorch;用pip3--user安装SDK并配置PATH;通过环境变量设置API_KEY和GROUP_ID;运行chat示例验证连通性;根据HTTP状态码(401/403/超时)定位鉴权或网络问题。495 收藏 -
 DeepSeekAI聊天入口官网是https://chat.deepseek.com,提供核心对话、多轮交流、深度思考模式、联网搜索及文档解析等功能。495 收藏
DeepSeekAI聊天入口官网是https://chat.deepseek.com,提供核心对话、多轮交流、深度思考模式、联网搜索及文档解析等功能。495 收藏 -
 微距切肥皂视频需三脚架俯拍、双柔光灯、哑光纯色背景、1080p/60fps录制;选用风干7天以上冷制皂,双色叠层,适度脱水;用美工刀与陶瓷刀分段切割,配合呼吸节奏;启用Seedance2.0解压模板参数。495 收藏
微距切肥皂视频需三脚架俯拍、双柔光灯、哑光纯色背景、1080p/60fps录制;选用风干7天以上冷制皂,双色叠层,适度脱水;用美工刀与陶瓷刀分段切割,配合呼吸节奏;启用Seedance2.0解压模板参数。495 收藏 -
 即梦AI无法保存作品需开启照片与视频写入权限、文件管理器访问权限,关闭电池优化,重置存储权限缓存,并授权DCIM/Pictures目录直写权限。495 收藏
即梦AI无法保存作品需开启照片与视频写入权限、文件管理器访问权限,关闭电池优化,重置存储权限缓存,并授权DCIM/Pictures目录直写权限。495 收藏