-

文字转AI视频的核心在于预见性和精细化,需将文字转化为视觉脚本,明确每句话对应的画面、镜头和情绪;2.通过具体化描述、使用精准的形容词和情绪词,如“月光洒落窗台、黑猫打盹、炉火跳动”,引导AI生成更符合预期的画面;3.声音是关键,需选择与主题匹配的旁白音色和背景音乐,并确保语速语调与画面协调,增强感染力;4.迭代优化必不可少,需反复调整提示词、尝试不同风格并剪辑组合片段,才能达到理想效果;5.提升叙事感染力需打破流水账,采用分镜思维,在文本中埋入视觉钩子与情感线索,如用“雨水滴落、灰蒙天空”表现伤心;6.
-
绘蛙AI修图在批量服务中的核心是作为“智能预处理器”和“标准化执行者”,通过建立“预设-批量-质检-微调”的闭环流程,实现效率与一致性的提升;2.它主要解决人工修图效率低、风格不统一、成本高等痛点,尤其适用于电商产品图、证件照等高标准化场景;3.优化工作流需包括前期筛选废片、分类命名、精细化定制并迭代修图模板、建立模板库、加强AI处理后的质检与精修环节,并通过客户反馈持续改进;4.面对不同摄影风格,应对策略分别为:纪实摄影应减少AI干预以保留真实感,创意人像宜用AI打底后由人工深度精修,高精度行业如珠宝美
-

利用CaktusAI提升培训材料制作效率的关键在于结合AI的高效生成能力与人类的专业判断,首先明确培训目标和受众,确保内容方向精准;2.通过精准的提示词引导AI生成结构化大纲和内容初稿,快速跳过从零开始的创作障碍;3.对AI生成内容进行批判性评估、事实核查、专业深度补充和语言风格优化,确保准确性和教学有效性;4.将AI生成的文本作为基础,结合多媒体形式增强呈现效果和互动性,提升学习体验;5.建立反馈循环,收集学习者意见以持续优化内容。必须始终坚持人工主导,避免过度依赖AI,保持内容的准确性、针对性和人文温
-
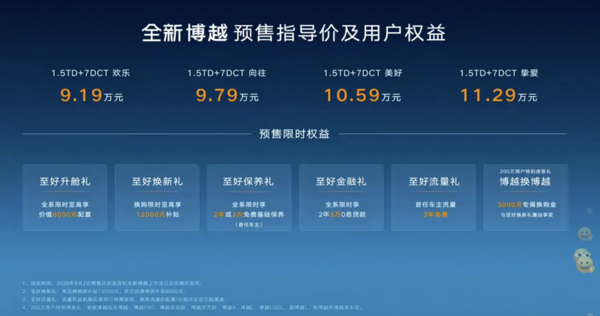
近日,新款吉利博越正式开启预售,全系共推出4款配置车型,均标配FlymeAuto智能座舱系统,预售价格区间为9.19万至11.29万元。据悉,该车型预计将在8月内完成上市交付。从外观来看,全新博越采用了时尚的双色车身设计,隐藏式B/C/D柱布局营造出明显的悬浮车顶视觉效果。新车提供17英寸、18英寸和19英寸三种规格的全新五辐轮圈选择,整体造型设计延续家族风格。配色方面,新增琉璃蓝、雨巷白、兰亭灰与水映银四种富有新中式美学韵味的车身颜色。车身尺寸方面,长宽高分别为4549mm、1865mm、1650mm
-

你可以通过复制粘贴、截图保存或浏览器插件等方式保存Perplexity的分析内容,支持TXT、DOCX、Markdown及手动转为PDF等格式。具体方法包括:1.手动复制内容至文本或文档工具;2.截图记录分析结果;3.使用Lightshot或Notion插件辅助保存;4.借助浏览器打印功能转存为PDF;此外,建议配合笔记软件整理内容,并注意保留引用链接以方便查证。
-

AI工具赚钱的核心在于将AI能力转化为用户价值并找到合适的商业模式。内容创作者可通过AI提升创作效率、扩展内容形式实现变现。具体路径包括:1.内容生成与优化,如自动生成文章、视频脚本、社交媒体帖子并提升SEO;2.个性化内容推荐,提高转化率;3.开发或使用AI辅助工具,如标题、关键词生成;4.打造AI驱动的互动体验,如聊天机器人、AI游戏。常见商业模式有订阅模式、按次付费、广告收入、联盟营销和内容付费。选择AI工具时应考虑自身需求、功能、易用性、价格、用户评价等要素,并优先试用免费版本。尽管AI提升效率显
-

不擅长拍摄的人可通过AI语言转视频制作短视频。具体步骤为:1.写清场景、氛围和细节的文字描述;2.使用如Seedance、即梦AI等工具,输入文字并选择风格与时长;3.生成后检查画面质量并进行后期编辑。适合普通人的工具有Seedance1.0、即梦AI、Deepseek手机版和MOKI。注意事项包括准确描述内容、控制视频长度、调整合适风格以及筛选输出结果,同时可加字幕和配乐提升效果。
-

Python解析XML因模块多样、易用性强被广泛使用,豆包AI可在代码生成和调试中提供有效帮助。1.选择Python解析XML因其标准库如ElementTree、minidom和lxml各具优势,适合不同场景;2.ElementTree解析流程简洁,可通过parse加载文件或fromstring解析字符串,快速获取节点信息;3.提取指定标签数据可用findall结合XPath表达式,灵活高效;4.处理带命名空间的XML需在查找时引入命名空间映射,豆包AI可根据示例自动识别并生成正确代码。
-

自媒体使用AI工具批量生成内容的核心在于将AI作为高效“思考伙伴”和“初稿生成器”,而非完全替代人类。1.首先明确内容定位、目标受众与核心价值,奠定创作基础;2.选择合适的AI工具组合,如文本、图片、视频生成工具;3.运用提示工程(PromptEngineering),通过设定角色、任务、上下文及输出格式提升生成质量;4.人工审核与精修,确保内容准确、连贯并注入个人观点;5.利用管理系统批量发布,并分析数据优化后续生成。为避免同质化,需在AI生成基础上加入独特视角、精细化Prompt、多源整合及反向操作识
-

写文章时内容准确和表达流畅同样重要,使用Deepseek满血版配合GrammarlyforChrome可提升效率。一、先用Deepseek满血版打草稿,帮助整理结构、润色语句并优化表达方式;二、复制到网页后,Grammarly自动检查语法、拼写并建议合适词汇及语气;三、搭配使用效果更好,Deepseek负责内容逻辑与自然表达,Grammarly确保语言规范与地道;四、注意小点包括避免Grammarly误判、不盲信Deepseek输出、留意浏览器兼容问题。
-

豆包AI编程助手的核心使用方法包括代码补全、错误排查、代码优化和学习辅助。在代码补全时,应明确输入意图并配合注释提示AI生成准确代码;遇到报错可将完整错误信息交给AI分析原因;已有代码可通过AI建议优化为更高效写法;还可用于实时学习语法和库用法。关键在于清晰表达需求以获得有效帮助。
-

7月1日,吉利汽车控股有限公司(以下简称“吉利汽车”)公布2025年6月的销量数据。数据显示,吉利汽车在6月取得了显著的销量增长,并上调了2025年的全年销量目标。根据公告,吉利汽车2025年6月的销量数据如下:总销量:236,036辆,同比增长42%;今年累计销售1,409,180量,同比增长47%。吉利品牌:193,024辆,同比增长59%;本年累计销量1,164,303辆,同比增长57%。其中,银河系列销量90,222辆,同比增长202%;本年累计销量548,408辆,同比增长232%。极氪品牌销量
-

近日,“2025中国企业出海高峰论坛”在深圳成功举办。在活动现场,沙特ISPSC综合服务中心CEO张涛在接受采访时表示,如今新能源汽车已经频繁出现在沙特街头。当被问及为何像沙特这样的石油大国也会青睐新能源汽车时,他指出,沙特消费者更倾向于科技感强的产品,而中国新能源汽车所具备的智能化优势恰好契合了这一需求。根据统计数据显示,中国汽车品牌在沙特市场占有率已突破50%。仅2025年第一季度,中国就向沙特出口汽车达25万辆。在投资方面,沙特主权财富基金已注资华人运通(高合汽车),阿联酋资本也入股蔚来汽车,卡塔尔
-

DeepSeek技术通过深度学习算法提升了Photoshop的智能修图能力,使其能自动调整图像参数并修复瑕疵,使用户无需深入了解复杂细节即可获得专业效果。使用时需注意:1.确保输入图像质量高;2.有时需人工调整细节;3.保存原始图像;4.不能完全替代专业修图师。DeepSeek技术对图像处理行业的影响包括:1.降低专业处理门槛;2.减少人工处理时间和成本;3.可能减少对专业人员需求,但更多是作为助手,帮助专注创意和细节。
-

Deepseek在教学视频脚本生成中的独特优势体现在结构化能力、内容广度与深度兼顾、多模态提示潜力和迭代效率四个方面。1.Deepseek能快速构建逻辑清晰的教学框架,解决内容层级混乱的问题;2.它提供全面且深入的知识点覆盖,如Git基础操作中不仅包含基本命令还涉及最佳实践;3.支持在脚本中整合视觉提示建议,提升视频呈现效果;4.可通过反馈快速调整优化脚本,显著提高内容迭代效率。