人工智能技术文章
-
 壹伴AI排版需通过四步实现行业风格精准匹配:一、调用预设六大行业模板;二、手动输入色值与授权字体;三、上传样例图反向提取风格;四、保存自定义模板为团队资产。266 收藏
壹伴AI排版需通过四步实现行业风格精准匹配:一、调用预设六大行业模板;二、手动输入色值与授权字体;三、上传样例图反向提取风格;四、保存自定义模板为团队资产。266 收藏 -
 简历逻辑松散因经历未围绕核心能力主线展开;需用DeepSeek四步重构:一提取能力锚点,二套用“目标-行动-影响”句式,三按能力线归集经历,四注入岗位专属动词与语境。489 收藏
简历逻辑松散因经历未围绕核心能力主线展开;需用DeepSeek四步重构:一提取能力锚点,二套用“目标-行动-影响”句式,三按能力线归集经历,四注入岗位专属动词与语境。489 收藏 -
 “设备已过期”提示源于鉴权失效,需依次校准系统时间、清除本地auth缓存、更换未绑定微信重申资格、手动刷新Token或通过客服人工重置设备状态。288 收藏
“设备已过期”提示源于鉴权失效,需依次校准系统时间、清除本地auth缓存、更换未绑定微信重申资格、手动刷新Token或通过客服人工重置设备状态。288 收藏 -
 需按四步操作:一选温柔音色如“晚安轻语”;二关背景音效并外接白噪音;三在文本中添加节奏控制指令;四创建专属智能体“兔耳阿姨睡前频道”实现一键朗读。163 收藏
需按四步操作:一选温柔音色如“晚安轻语”;二关背景音效并外接白噪音;三在文本中添加节奏控制指令;四创建专属智能体“兔耳阿姨睡前频道”实现一键朗读。163 收藏 -
 DeepSeek模型本地部署失败的三大原因及解决步骤:一、检查GPU显存是否满足最低要求(7B需≥12GB,13B≥16GB,67B≥48GB或量化);二、更新NVIDIA驱动至CUDA版本要求的最低版本;三、验证PyTorchCUDA可用性并确保环境变量与版本匹配。121 收藏
DeepSeek模型本地部署失败的三大原因及解决步骤:一、检查GPU显存是否满足最低要求(7B需≥12GB,13B≥16GB,67B≥48GB或量化);二、更新NVIDIA驱动至CUDA版本要求的最低版本;三、验证PyTorchCUDA可用性并确保环境变量与版本匹配。121 收藏 -
 需借助WorkBuddy图像处理自动化能力批量裁切导出多平台封面图:一、预设并导入多尺寸模板;二、批量绑定原图与模板自动处理;三、启用AI锚点智能裁切防主体偏移;四、按平台命名规则自动归类输出;五、导出ZIP包并用CSV校验尺寸合规性。316 收藏
需借助WorkBuddy图像处理自动化能力批量裁切导出多平台封面图:一、预设并导入多尺寸模板;二、批量绑定原图与模板自动处理;三、启用AI锚点智能裁切防主体偏移;四、按平台命名规则自动归类输出;五、导出ZIP包并用CSV校验尺寸合规性。316 收藏 -
 NameGPT、Namelix、阿里云起名通、百度智能起名、美名轩是五款主流AI起名工具,分别侧重对话精调与Logo联动、国际合规与商标规避、工商核名预审、社交传播避雷、周易卦象与硬科技适配。480 收藏
NameGPT、Namelix、阿里云起名通、百度智能起名、美名轩是五款主流AI起名工具,分别侧重对话精调与Logo联动、国际合规与商标规避、工商核名预审、社交传播避雷、周易卦象与硬科技适配。480 收藏 -
 使用Beautiful.ai的智能模板、自动对齐、智能占位符和主题引擎功能,可高效实现幻灯片布局统一:首先选择预设模板自动适配内容;其次利用绿色参考线进行元素对齐;再通过智能占位符动态调整内容大小;最后应用主题引擎统一字体与配色,确保整体风格协调一致。159 收藏
使用Beautiful.ai的智能模板、自动对齐、智能占位符和主题引擎功能,可高效实现幻灯片布局统一:首先选择预设模板自动适配内容;其次利用绿色参考线进行元素对齐;再通过智能占位符动态调整内容大小;最后应用主题引擎统一字体与配色,确保整体风格协调一致。159 收藏 -
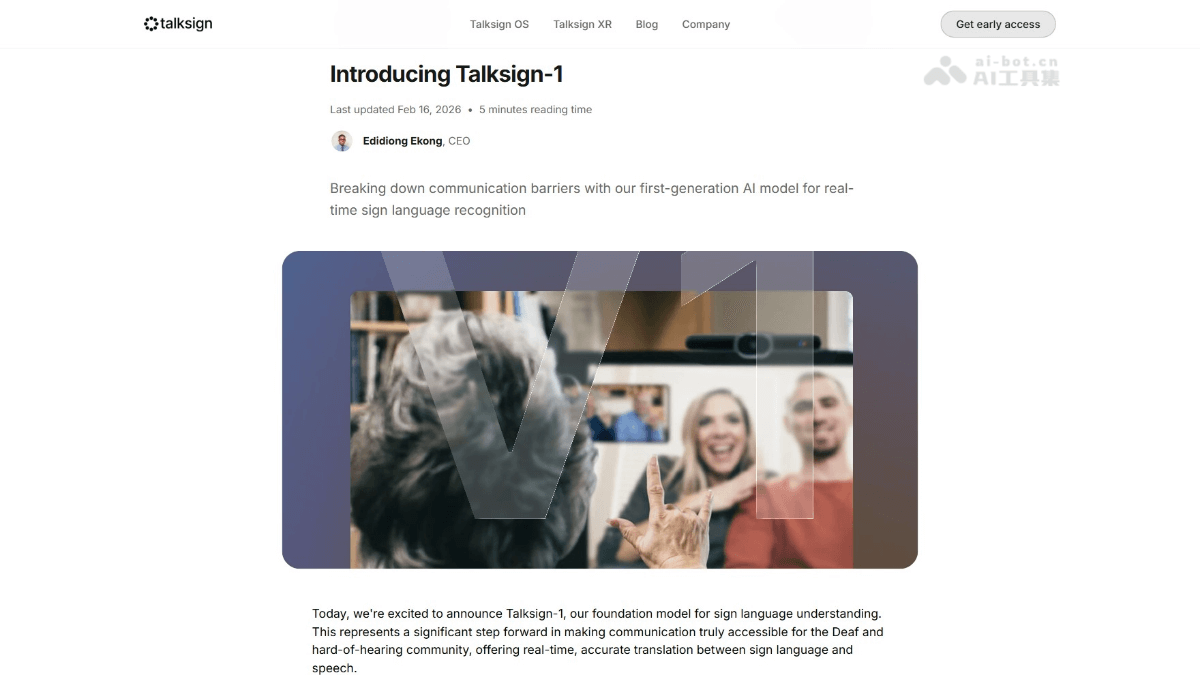 Talksign-1是什么Talksign-1是专为美式手语(ASL)设计的AI实时翻译模型,支持双向转换,能通过摄像头捕捉3D人体关键点识别250个ASL词汇,或将语音/文字转为手语视频。模型基于TensorFlow/Keras构建,采用Transformer增强CNN架构,推理延迟低于100毫秒,可在浏览器端运行。模型训练自WLASL2000数据集,目前支持孤立手势识别,适用于教育、医疗、职场等场景,致力于提升听障群体的沟通无障碍体验。Talk340 收藏
Talksign-1是什么Talksign-1是专为美式手语(ASL)设计的AI实时翻译模型,支持双向转换,能通过摄像头捕捉3D人体关键点识别250个ASL词汇,或将语音/文字转为手语视频。模型基于TensorFlow/Keras构建,采用Transformer增强CNN架构,推理延迟低于100毫秒,可在浏览器端运行。模型训练自WLASL2000数据集,目前支持孤立手势识别,适用于教育、医疗、职场等场景,致力于提升听障群体的沟通无障碍体验。Talk340 收藏 -
 Kimi深度SWOT分析需结构化提示词、K2-Thinking多步推理、行业知识库锚定、冲突验证及API动态权重赋值五步协同,确保结论具象、可验证、可执行。184 收藏
Kimi深度SWOT分析需结构化提示词、K2-Thinking多步推理、行业知识库锚定、冲突验证及API动态权重赋值五步协同,确保结论具象、可验证、可执行。184 收藏 -
 OpenClaw是本地主权代理,具备操作系统级权限、端到端本地数据闭环、多态渠道集成与多智能体路由调度;而ChatGPT等为远程托管接口,仅提供对话式文本输出与云端数据中转。178 收藏
OpenClaw是本地主权代理,具备操作系统级权限、端到端本地数据闭环、多态渠道集成与多智能体路由调度;而ChatGPT等为远程托管接口,仅提供对话式文本输出与云端数据中转。178 收藏 -
 PyCharm启用AI辅助需按插件类型配置:官方AIAssistant要求2023.2+版本并登录JetBrains账户;Tabnine支持本地Lite模型,需手动下载;CodeWhisperer依赖AWS凭证;CodeGeeX2需关闭签名验证后离线安装。189 收藏
PyCharm启用AI辅助需按插件类型配置:官方AIAssistant要求2023.2+版本并登录JetBrains账户;Tabnine支持本地Lite模型,需手动下载;CodeWhisperer依赖AWS凭证;CodeGeeX2需关闭签名验证后离线安装。189 收藏 -
 腾讯元宝官方登录入口为https://yuanbao.tencent.com,支持网页端、APP及微信小程序三端同步访问,具备双模型协同、深度文档处理、自然语音交互与个性化创作辅助六大核心功能。456 收藏
腾讯元宝官方登录入口为https://yuanbao.tencent.com,支持网页端、APP及微信小程序三端同步访问,具备双模型协同、深度文档处理、自然语音交互与个性化创作辅助六大核心功能。456 收藏 -
 高效生成专业招聘文案的关键是设计结构化、有上下文引导的提示词,涵盖明确岗位要素、复合角色场景约束、竞品对比优化、分阶段生成校验及注入企业真实语料五种方法。416 收藏
高效生成专业招聘文案的关键是设计结构化、有上下文引导的提示词,涵盖明确岗位要素、复合角色场景约束、竞品对比优化、分阶段生成校验及注入企业真实语料五种方法。416 收藏 -
 ChatGPT可实现四类舆情分析:一、结构化提示零样本分类;二、Embedding+余弦相似度量化打分;三、JSON格式多维度细粒度解析;四、规则词典混合增强校验。398 收藏
ChatGPT可实现四类舆情分析:一、结构化提示零样本分类;二、Embedding+余弦相似度量化打分;三、JSON格式多维度细粒度解析;四、规则词典混合增强校验。398 收藏