-

使用豆包AI生成Linux运维脚本的关键在于提对问题并适当修改。1.提问要具体明确,包括路径、时间、命令等细节,如“请用find命令写一个每天凌晨2点清理/tmp目录下7天前文件的crontab脚本”;2.结合实际场景添加判断逻辑,例如检查文件是否存在、权限是否正确,提升脚本健壮性;3.可快速生成定时任务或监控脚本模板,如生成每小时检查磁盘使用率并邮件告警的脚本;4.生成后务必验证测试,检查语法、运行副作用、安全风险,并补充注释以便维护。掌握“精准提问+后期优化”的思路,可大幅提升运维效率。
-

豆包AI可以帮助设计数据库Schema,但需明确需求。1.先说明业务场景和实体关系,如电商系统中的用户、商品、订单等及其关联方式;2.提供字段示例和约束条件,如指定主键、唯一字段、可为空字段等;3.区分SQL与NoSQL适用场景,根据数据库类型获取不同设计建议;4.可让AI优化已有Schema,检查冗余字段、索引缺失等问题。
-

多模态AI因需同时处理图像、文本、音频等多样数据,其算力和硬件需求远超单模态模型。1.多模态AI更“吃”资源的原因在于各类数据(如视频、图像、文字)本身复杂度不同,且融合阶段(如跨模态注意力机制)带来额外计算负担;2.硬件配置建议包括使用高性能GPU集群(如A100或H100)、大容量内存(至少64GBRAM、40GBVRAM/GPU)、高速存储(NVMeSSD)、高带宽网络(如NVLink);3.优化算力使用的方法有模型压缩、异构计算利用、数据预处理与缓存、分布式训练策略及选择合适框架(如PyTorch
-

DeepSeek和VSCode的结合可以显著提升程序员的生产力。1.安装最新版本的VSCode并从DeepSeek官网下载插件。2.DeepSeek提供代码自动完成、错误检测和优化功能。3.调整插件设置和使用快捷键优化体验。4.DeepSeek在Python和JavaScript上表现出色,但需根据具体需求选择工具。总之,逐步深入了解并调整使用方式,可以找到最适合自己的开发流程。
-

欧盟委员会近日正式公布通用人工智能行为准则的最终文本,目的是帮助企业更有效地遵循欧盟关于人工智能的法律规定。这项行为准则由13名独立专家共同起草,起草过程中广泛吸收了来自1000多家中小型企业、学术机构、民间团体及大型语言模型开发者的建议。据了解,行为准则的制定历时数月,期间多次公开征求意见,力求内容全面且具备可操作性。目前,欧盟委员会连同其27个成员国将对该准则进行深入评估,并决定是否通过。若获得通过,人工智能模型的提供方将可以选择是否签署该准则。欧盟有关人士表示,签署该行为准则的企业,在向监管机构展示
-

Gemini可以处理JSON数据,但需明确指令与格式示例。1.直接指定格式,如“请以JSON格式返回结果”;2.提供结构模板,如字段名和类型;3.限制字段数量,减少错误概率;4.避免模糊描述,应具体说明所需字段;5.处理复杂结构时分步骤提示,如嵌套对象或数组;6.注意常见问题,如格式错误、字段缺失、中文字符支持及嵌套过深等。只要指令清晰,Gemini能够准确生成或修改符合要求的JSON数据。
-

Deepseek与Synthesia的结合通过自动化内容生成与视频制作大幅提升效率与质量。首先,Deepseek根据受众、时长与主题生成结构严谨、风格定制的文案脚本,实现秒级输出与快速迭代;其次,Synthesia将文本转化为带有自然表情、动作与唇形同步的虚拟数字人视频,省去拍摄与剪辑等繁琐流程;最终,在保证专业性与一致性的同时,使高质量视频内容生产更高效触手可及。
-

Gemini通过多模态理解和推理能力辅助基因数据解析与生物信息学分析。①它虽不直接运行底层工具,但能解读常见格式如VCF、BED、FASTA和BAM,并指导关键字段含义及质量判断;建议输入前说明数据来源、关注变异类型并提供示例片段。②在变异注释方面,它结合ClinVar、COSMIC、KEGG等数据库评估变异致病性、功能影响及临床意义。③在流程搭建时,可提供建议如参数设置、过滤策略、参考基因组选择等。④使用时需注意其局限性,如无法访问私有数据、不能执行本地计算、回答基于已有知识推测而非实际运算结果,因此需
-

文心一言生成的图片不适合直接用于商业用途。1)版权归百度公司,需许可才可商用。2)个人学习或非盈利展示可使用,但需注明来源。3)如需商用,可联系百度获取许可、修改图片或寻找替代资源。
-

写出有效提示词的关键在于具体描述与留白想象结合。一是先描述基础场景,如“沙漠”“未来城市”,再加入反差元素,如“漂浮的鲸鱼”“发光的树”。二是使用氛围词汇,如“黄昏”“雾气弥漫”“低饱和度色调”,增强画面感。三是借助Deepseek优化提示词,将创意目标转化为专业英文提示,添加风格关键词如“Cinematiclighting”。四是微调图像风格,使用后缀词控制比例、模型版本和风格倾向,如--stylevivid或艺术流派关键词。五是不断试错调整,保留成功结构并尝试新组合,细微改动也能带来显著变化。
-

调用IBMWatson的NLP服务主要包括以下步骤:1.创建IBMCloud账号并开通WatsonNaturalLanguageUnderstanding服务;2.获取API密钥和服务URL,建议保存至配置文件或环境变量;3.使用Python构造请求头、请求体并发送POST请求进行API调用。整个流程中需注意认证信息正确性、请求格式规范以及免费版的频率限制等问题。
-
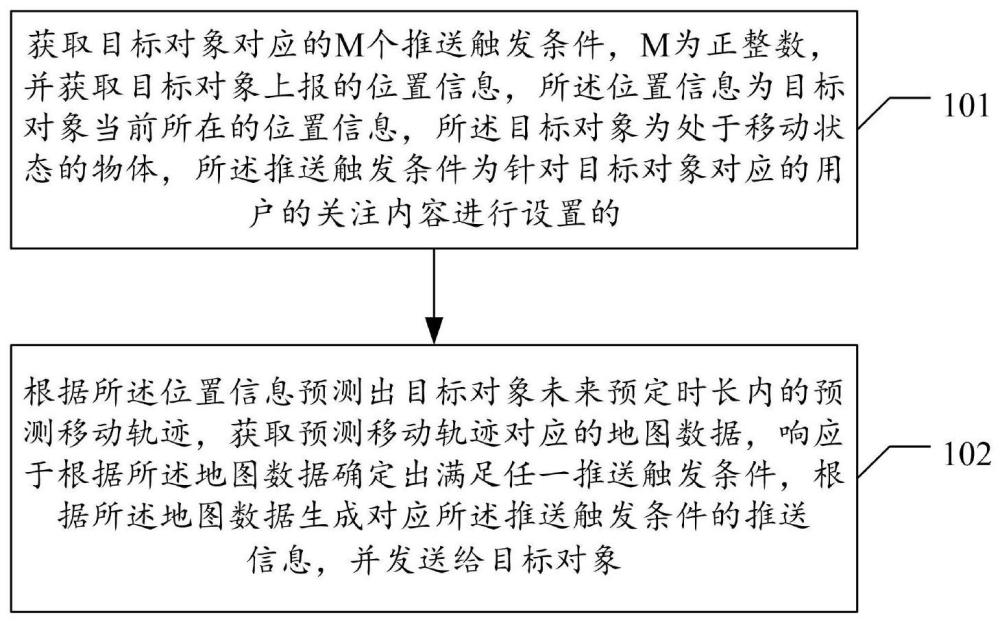
天眼查信息显示,北京百度网讯科技有限公司于2025年3月14日公开了一项名为“信息推送方法、装置、电子设备及存储介质”的专利,专利申请公布号为CN119622077A。该发明提供了一种信息推送的方案,适用于智能交通、地图服务和物联网等人工智能相关领域。其核心方法包括:获取目标对象的M个推送触发条件(其中M为正整数),并接收该目标对象上报的当前位置信息,所述目标对象为处于运动状态的物体;基于该位置信息预测目标对象在未来预定时间内的移动路径,并提取相应地图数据;当根据地图数据判断满足任一推送条件时,系统将依据
-

DeepSeek私有化部署的核心步骤包括模型获取、环境准备、推理服务搭建和API接口暴露。首先,从官方或HuggingFace等平台下载模型文件,选择合适版本如DeepSeek-Coder或DeepSeek-MoE,并确保存储空间充足。其次,准备高性能服务器,配备NVIDIAGPU(如RTX3090/4090或A100/H100)、兼容的Linux系统、CUDAToolkit和cuDNN等必要软件环境。接着,使用vLLM、TGI或Triton等高效推理框架搭建推理服务,推荐采用Docker容器化部署以简化
-

DeepSeek和VSCode的结合可以显著提升程序员的生产力。1.安装最新版本的VSCode并从DeepSeek官网下载插件。2.DeepSeek提供代码自动完成、错误检测和优化功能。3.调整插件设置和使用快捷键优化体验。4.DeepSeek在Python和JavaScript上表现出色,但需根据具体需求选择工具。总之,逐步深入了解并调整使用方式,可以找到最适合自己的开发流程。
-

生成AI证件照时,肤色调整通过复杂的图像处理技术和算法实现,使照片看起来更加自然和真实。1.肤色检测和分离技术通过机器学习模型准确识别皮肤区域。2.调整色调、饱和度和亮度,考虑个人肤色类型和光照条件。3.使用高级技术如深度学习模型和A/B测试来优化效果,确保符合不同地区和文化的审美标准。