-

解决蝉镜同步失败问题需先检查网络连接,切换至Wi-Fi或重启路由器;2.确保蝉镜App已更新至最新版本;3.退出账号并重新登录,或清除App缓存与数据;4.检查手机系统是否授予蝉镜访问联系人的权限;5.若仍无法解决,联系蝉镜官方客服获取技术支持;该方法可有效排除常见同步故障,确保联系人数据正常备份至云端,以完整句结束。
-

将AI牌类教学工具与豆包联用能系统提升牌技,关键在于构建精确场景、提出深入问题、实战复盘分析、深化规则理解。首先,需详细描述手牌、对手风格、筹码量等要素以确保AI分析质量;其次,提问要具体,如探讨加注的风险收益或对手反应;再次,实战后利用豆包复盘关键牌局,指出逻辑漏洞并量化失误影响;最后,通过AI解释复杂概念如EV、底池赔率,构建清晰决策模型。结合AI模拟与实战练习,形成“学-练-思-调”闭环,持续优化策略与心态,最终实现从理论到实战的融会贯通。
-

遇到ChatGPT插件开发中的环境依赖冲突或虚拟环境配置问题,通常源于Python环境管理不当或依赖版本不兼容;1.使用venv、poetry或pipenv创建独立虚拟环境,避免全局安装导致的冲突;2.在requirements.txt或pyproject.toml中明确指定依赖版本,优先使用==锁定版本并用pipcheck检查冲突;3.开发插件时模拟目标平台环境,避免使用不支持的库,并提前测试打包部署。做好隔离、控制版本、提前测试是关键。
-

PerplexityAI目前不支持原生语音搜索,但可通过以下方法实现语音转文本查询:1.使用手机或电脑的语音助手(如Siri、GoogleAssistant)将语音转为文字后复制粘贴至Perplexity;2.通过浏览器插件如Speechnotes或Dictanote实现网页端语音输入;3.开发者可调用WebSpeechAPI和PerplexityAPI搭建自定义语音搜索界面;4.使用时需注意环境噪音、语速及语言支持等因素以提升识别准确率。
-
找到豆包AI:在手机应用商店搜索“豆包”或“字节跳动AI”,下载安装后用手机号或微信、抖音等账号登录即可进入简洁的对话界面;2.学会高效提问:用自然语言直接提问、内容创作、信息总结或角色扮演,并善用语音输入提升效率,同时通过多轮对话逐步细化需求比一次性输入长指令更有效,还能通过设定角色让回答更专业精准。
-

豆包和DeepSeek通过协同工作,提升文章创作与情感润色的效率。豆包生成结构化初稿,DeepSeek进行情感润色,使文章更加生动。具体步骤包括:1.使用豆包生成文章初稿,2.用DeepSeek润色文章,使其更具感染力。
-

使用Deepseek满血版和QuillbotPremium联动可有效提升写作表达。一、Quillbot用于基础润色,使句子更通顺自然;Deepseek则理解上下文并调整语气风格,实现从逻辑到表达的全面提升。二、使用技巧包括分步处理、设定语气、检查逻辑一致性。三、适用于论文润色、营销文案优化、日常写作提档。四、注意结合人工判断、控制输入长度、尝试多种模式组合,以获得最佳效果。
-

PerplexityAI在文档向量化中可能采用了基于Transformer架构的预训练语言模型,如BERT、RoBERTa或GPT系列中的嵌入模型。1.它通过自注意力机制捕捉上下文依赖关系,生成高质量语义向量;2.文本经分词后通过模型处理,输出固定长度的数值向量作为文档嵌入;3.这些嵌入能编码复杂语义信息,实现对多义词和上下文的理解;4.PerplexityAI可能进一步微调基础模型,以适配其知识库领域和查询模式。
-

使用豆包AI辅助生成Python单元测试代码能显著提升效率。其核心方法是将函数逻辑、参数类型及预期行为清晰描述给AI,它便能基于常规情况、边界值和异常输入生成对应测试用例;例如对字符串处理函数,AI可根据提供的示例代码快速构建测试场景。适用场景包括基础数据类型处理、输入输出明确的函数以及无测试覆盖的老项目;但涉及数据库、网络请求或复杂状态管理的函数仍需手动调整mock逻辑。提高生成质量的关键在于明确提示词(如指定unittest或pytest风格)、说明期望覆盖范围(如正常值、空值、非法输入)及多轮交互优
-
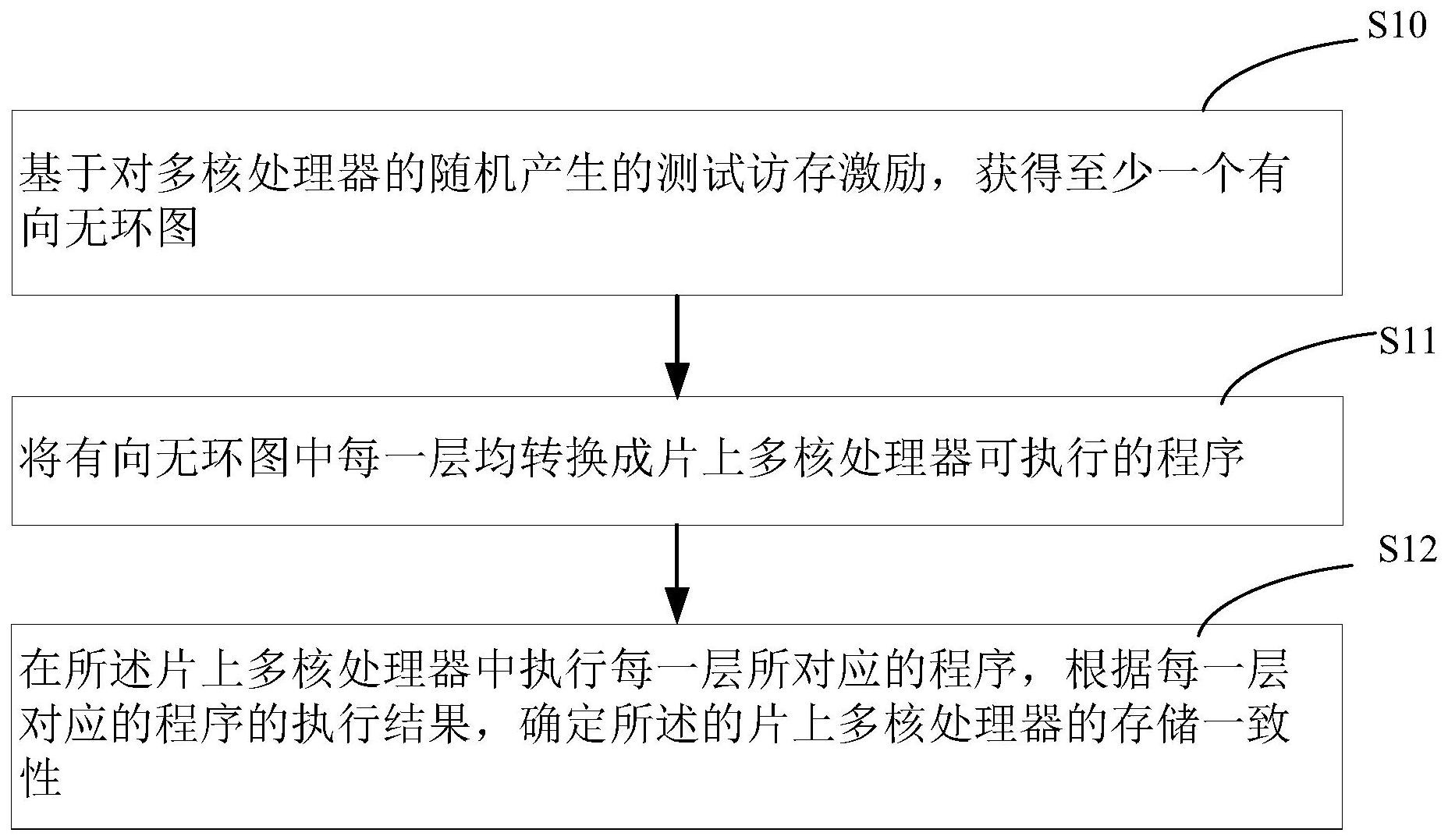
天眼查信息显示,深圳云豹智能有限公司于2025年2月14日公开了一项名为“片上多核处理器的存储一致性验证方法、系统、存储介质及设备”的专利,专利申请公布号为CN119440920A。该发明提供了一种用于片上多核处理器的存储一致性验证的方案,包括方法、系统、存储介质及设备。其方法具体包括以下步骤:首先根据对多核处理器生成的随机测试访存激励,构建至少一个有向无环图;随后将每个有向无环图中的各层转化为可在片上多核处理器上运行的程序代码;最后在片上多核处理器中执行这些程序,并依据每层程序的执行结果来判断该多核处理
-

多模态AI与传统AI的区别在于信息处理方式和应用场景。1.多模态AI可同时处理多种数据类型,如文字、图像、音频和视频,而传统AI仅限于单一数据输入;2.多模态AI通过跨模态融合技术实现复杂任务,如自动驾驶整合视觉与雷达信息,而传统AI依赖特定算法适用于结构化任务;3.多模态AI应用于智能助手、医疗诊断等需多维信息分析的场景,而传统AI适合资源有限环境下的简单任务;4.多模态AI对算力和数据要求高,部署成本大,而传统AI模型小、训练快、部署容易。
-
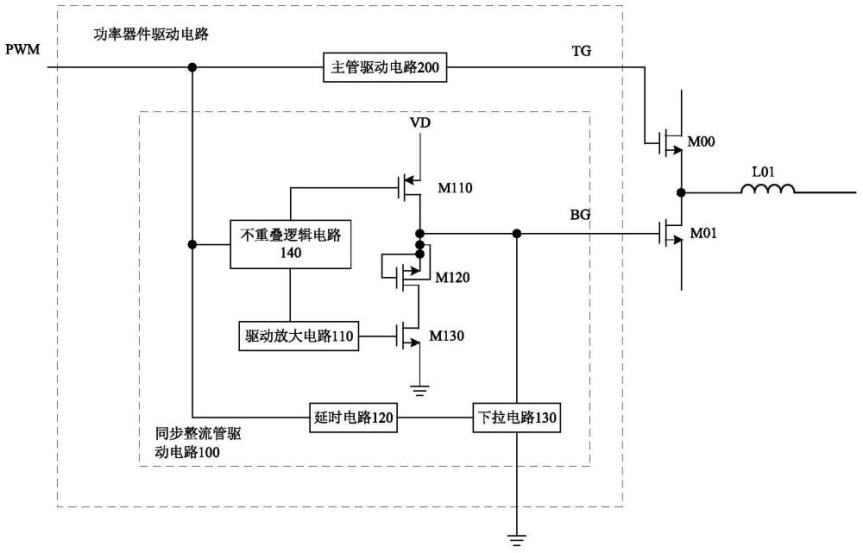
天眼查信息显示,杰华特微电子股份有限公司近期获得了一项名为“用于开关电路的功率器件驱动方法、驱动电路及开关电路”的专利,授权公告号为CN111585425B,授权公告日期为2025年3月14日,申请时间为2019年8月21日。该发明涉及一种应用于开关电路中的功率器件驱动方法、相应的驱动电路以及开关电路结构。该开关电路包含主开关管、同步整流管和感性元件。在开关信号指示同步整流管由导通状态切换至关断状态,同时主开关管由关断状态进入导通状态时,利用MOS管的体效应特性,将同步整流管驱动极的电压拉低至低于其阈值电
-

笔尖AI的“对话记忆”功能通过引导和迭代帮助AI理解上下文并锁定重点,核心方法包括:1.明确初始指令,清晰表达目标;2.持续关联上下文,保持话题连贯;3.及时追加或修正指令,确保内容贴合需求;4.合理使用否定指令,规避不必要内容;5.阶段性总结确认,检验是否偏离主题。AI依靠NLP模型提取关键词、分析语义关系、处理指代及维护对话状态来理解长对话,但存在记忆长度限制、理解偏差和任务切换干扰等局限,需通过控制对话长度、定期重申目标、使用清晰语言、专注单一任务等方式避免“失忆”。掌握这些技巧可有效提升AI协作效
-

生成不同国家证件照的AI系统需要考虑技术实现、文化差异和法规要求。1)设置背景颜色,如美国为白色,日本为浅蓝色,德国为浅灰色。2)调整面部表情,美国和英国要求自然表情,法国允许轻微微笑。3)设定头部姿势,中国要求正对镜头,印度允许轻微侧脸。通过灵活的参数设置和不断优化,可以生成符合各国标准的高质量证件照。
-

文心一言生成的表格可以通过以下步骤复制:1.右键点击表格,选择“复制”或使用快捷键Ctrl+C。2.在其他文档或软件中使用Ctrl+V粘贴。复制时可能遇到格式丢失或数据不完整的问题,可通过查看源代码并复制HTML代码来解决。