-

SpringAI官方不提供DeepSeek的开箱即用starter,需手动实现ChatModel接口并用WebClient对接其OpenAI兼容API;配置须避免使用无效的spring.ai.providers.deepseek前缀,而应通过环境变量或自定义配置注入APIKey。
-

Midjourney不解析相机参数,而是响应语义锚点;DSLR比冗长参数更可靠,因模型对其有强光学先验;胶片需带ISO与特征描述(如Kodachrome64,finegrain);--s调控颗粒频谱,--styleraw必开;版本切换使参数失效,应锁定v6.6配合特定设置。
-

在ComfyUI中用Qwen-Image-2512生成户外品牌海报的正确方法是:①开头明确指令“生成3个不同视觉策略的户外品牌海报备选方案,编号为①②③,每个方案独立成图,不可混合”;②用英文分号“;”严格分隔三个方向,编号后紧跟冒号且无空格;③每个方向须完整包含品牌名、核心产品、主视觉动作、风格关键词、文字排版要求五要素,缺一则失效;④方向差异须基于可执行的视觉参数(如场景、媒介、字体字号、色偏参数等),禁用抽象风格词。
-

在解释SoMin公司的广告文案和横幅生成功能时,经常有人会问,是否用ChatGPT取代了GPT-3,或者是否仍然在运行过时的模式。“我们没有,也不打算这样做。”SoMin公司发言人给出这样的回答,尽
-

每年,全世界有超过 6900 万人饱受创伤性脑损伤的折磨,他们中的许多人无法通过语音、打字或手势进行交流。如果研究人员开发出一种技术,可以通过非侵入性的方式直接从大脑活动解码语言
-
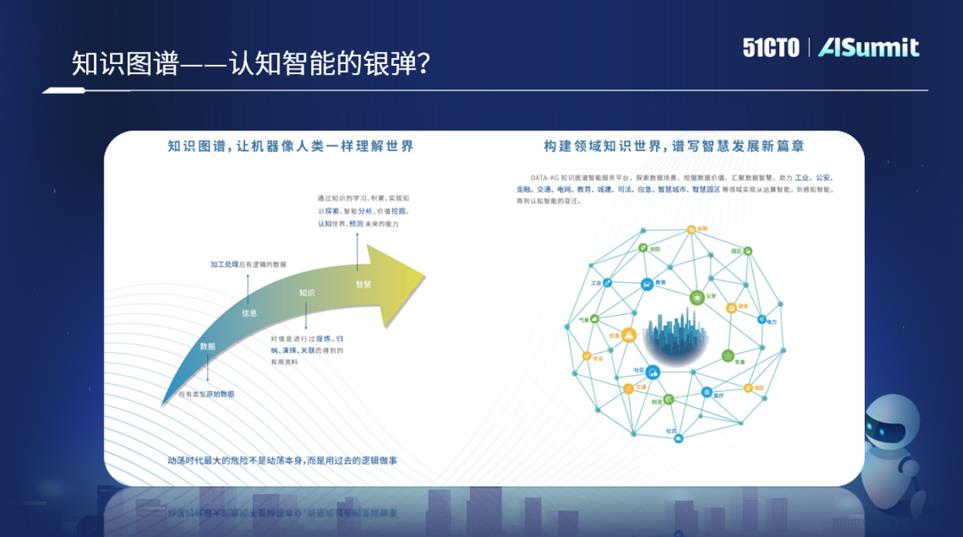
2022年8月6日-7日,AISummit 全球人工智能技术大会如期举办。在7日下午举办的《AI赋能产业实践》分论坛上,泰凡科技副总经理马国宁带来了《图绘万象,从柯尼斯堡到百业赋能》的主题
-

不久前落幕的2022世界机器人大会,集中展示了机器人在制造、建筑、医疗、农业、矿山、物流等诸多领域的创新应用,成为透视我国机器人产业发展趋势的重要窗口。近年来,我国机器人产业
-
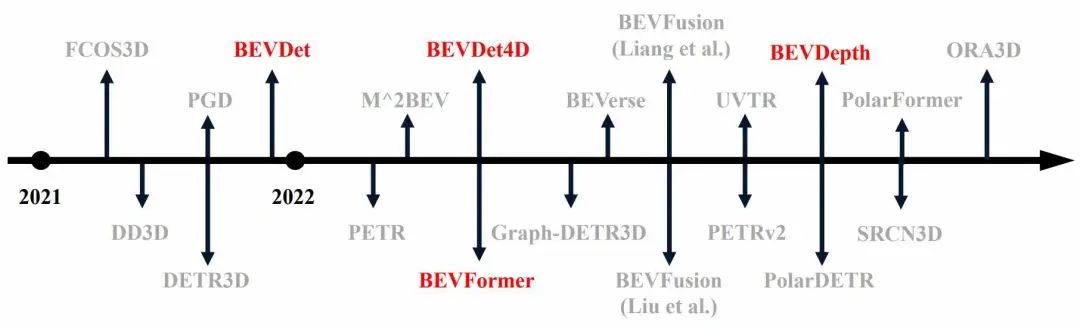
背景自动驾驶是逐渐从预言阶段向工业化阶段的一个过渡,具体表现可分为4点。首先,在大数据的背景下,数据集的规模在快速扩张导致以前在小规模数据集上开发原型的细节会被大量过滤掉
-

智能建筑最重要的组成部分之一是人工智能。没有它,一栋建筑很难被认为是智能的,因为没有它,业主和管理者将无法为他们的租户提供最安全、最舒适的环境。一个建筑平台要从多个来源收
-
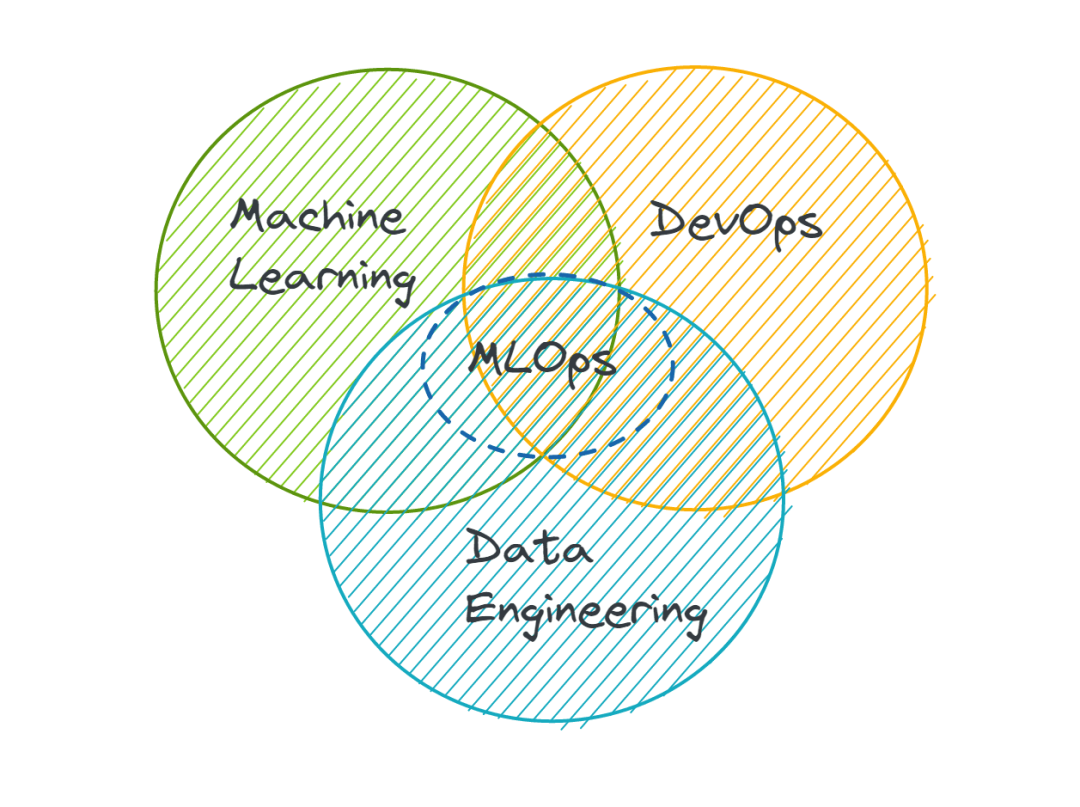
你有兴趣成为一名 MLOps 工程师吗?今天详细了解 MLOps 工程师角色。所以已经建立了一个机器学习模型。它在验证数据集上达到了预期的性能。很高兴能够应用数据科学和机器学习技能来构建此
-
DeepRec(PAI-TF)是阿里巴巴集团统一的开源推荐引擎(https://github.com/alibaba/DeepRec),主要用于稀疏模型训练和预测,可支撑千亿特征、万亿样本的超大规模稀疏训练,在训练性能和效果方面均有
-

5月9日消息,承诺让用户沉浸在虚拟世界中的元宇宙技术曾风靡一时。但随着ChatGPT等生成式人工智能技术的兴起,三年后元宇宙业务已经被商界所抛弃。2021年,Facebook创始人马克·扎克伯格(MarkZuckerberg)将市值万亿美元的公司更名为Meta。经过一番大肆宣传后,元宇宙技术成为科技界痴迷的对象,并迅速赢得投资者的青睐。然而,缺乏连贯的产品愿景最终导致元宇宙走向衰落。当科技行业转向生成式人工智能这一更有前途的新趋势,元宇宙就注定要失败。宏大承诺扎克伯格曾声称元宇宙将是互联网的未来。在扎克伯
-

ChatGPT,现在有iOS版本了!就在几个小时前,OpenAI官方突然大放送,官宣ChatGPT正式推出iOSAPP。瞬间冲上苹果商店免费榜第二名,效率榜第一名。(第一是拼多多海外版)这回,真的是ChatGPT的iPhone时刻了。想象一下,全球有着几十亿智能手机用户,占到人口总数将近90%。而很快大家都能在手机上体验ChatGPT了。看得人们直呼:见证历史!人们还没有意识到,世界已经改变了。还有人说看到大家能如此自然地在iOS上和ChatGPT聊天,这真的非常令人激动,是一场胜利!目前,这场狂欢暂时还
-

当技术与商业之间产生巨大矛盾时,JuergenSchmidhuber才会被公众惦记起来。从四月那封暂停人工智能技术研发的公开信,到本月初为了能更“自由”的谈论AI风险而离开谷歌的GeoffreyHinton。本世纪最具想象力也最具争议的技术终于站在了最后的十字路口。最近两年,JuergenSchmidhuber的风头一度被获得图灵奖的人工智能三巨头(YoshuaBengio、GeoffreyHinton和YannLeCun)所盖过,以致于大众无意识间将这位人工智能思想家与技术先驱放到了一个相对低估的位置。
-

IT之家5月16日消息,iPhone15系列将在今年的9月份到来,预计将会推出iPhone15、iPhone15Plus、iPhone15Pro以及iPhone15ProMax四款机型。今年的iPhone15系列将会额外引人注目,相较于iPhone14系列会有较大的变化,在此前的IT之家报道中有过详细介绍。其中屏幕更大的iPhone15ProMax预计将会是iPhone史上首次搭载潜望镜头的iPhone机型,可以获得更好的变焦能力,从而提升iPhone的拍照体验。之所以潜望镜头会是Max机型独占是因为镜头