-
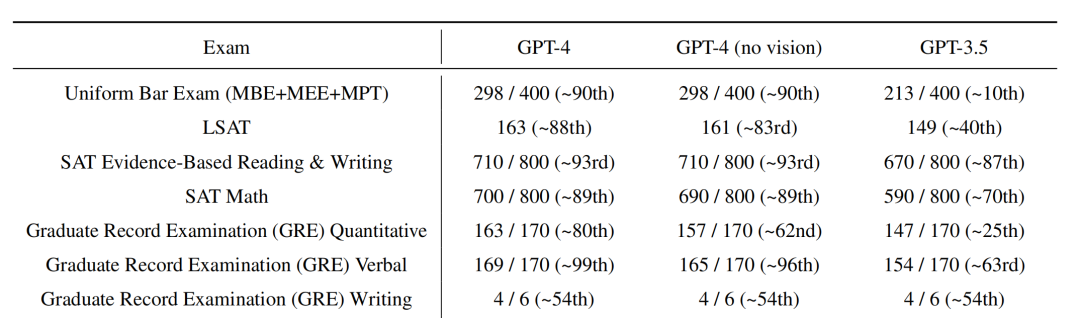
OpenAI昨天发布了GPT-4,试用了一下确实很不错。在我主要关心的故事生成方面,与ChatGPT生成出来的故事相比,GPT-4文笔更佳细节更多,更擅长生动具体的描绘,情节也开始出现一些有趣的转折。
-

自Google提出Vision Transformer(ViT)以来,ViT渐渐成为许多视觉任务的默认backbone。凭借着ViT结构,许多视觉任务的SoTA都得到了进一步提升,包括图像分类、分割、检测、识别等。然而,训练ViT并非易
-
当你在PimEyes上搜索自己的照片时,你会看到很多自己的照片,还有跟你长得很像的人。不过,这个工具在进行算法训练的时候,使用的并不是用户授权的照片,而是基于整个网络各个平台的照
-

Python 是全球最流行的编程语言之一,拥有越来越多的库和框架。看看最新的。Python 是全球最流行的编程语言之一,拥有越来越多的库和框架来促进 AI 和ML 开发。Python 中有超过 250 个库,要知道
-

自 2020 年 GPT-3 横空出世以来,ChatGPT 的爆火再一次将 GPT 家族的生成式大型语言模型带到聚光灯下,它们在各种任务中都已显示出了强大的性能。但模型的庞大规模也带来了计算成本的上升和
-

通义灵码支持通过结构化注释+快捷键快速生成函数:需在空行写含「需求」「输入」「输出」的多行注释,光标置于其下空行,按Alt+P触发;可Tab整段采纳或Ctrl+↓逐行采纳,也可用对话面板发指令精准控制生成。
-

新生乡2026年育儿补贴申领指南明确:通过支付宝搜索“育儿补贴”进入申领入口;首次申领需备齐婴幼儿及申请人身份、婚姻/抚养权等材料;流程为线上填写提交后查进度;往年已申领者可直接“继续申领”。
-

可灵AI实现“信展开字浮现”需分阶段锚定纸张形变与墨迹显影的耦合时序,主流路径有三:一、图生视频+首尾帧约束,用闭合信封与展开留白图驱动三阶段物理模拟;二、文本生成视频+双轨提示词,按时间轴精确描述展开与显字因果过程;三、分镜合成法,分别生成折纸动画与水墨显影视频后通过图层混合精准叠加。
-

ClawBot能记住之前的聊天内容,其记忆能力依赖于本地存储机制与可选的云端同步路径。以下是实现该能力的多种技术方案:一、本地持久化记忆系统(默认启用)ClawBot的核心记忆结构基于磁盘文件系统,所有对话历史、用户偏好、项目上下文均以Markdown格式长期保存在本地工作区,不受重启或断电影响。该机制完全离线运行,无需网络连接即可调用全部历史记录。1、打开终端,进入ClawBot主工作目录:/root/.clawdbot/agents/main/。2、确认存在MEMORY.md
-

若抖音AI抢票失败,需依次完成AI抢票资格认证、配置多端协同环境、设置精准票源监听、启动AI自动化执行器、触发应急补位机制五步操作。
-

智谱清影当前不支持物理级金属反射特效,需通过三种路径实现:一、智谱清影生成带Alpha通道素材后在AE中添加CCLightSweep、Glow及Particular粒子增强闪烁;二、用智谱清影输出运镜与灯光参数驱动C4D+Octane渲染金属材质与实时光追反射;三、通过深度优化提示词(如anodizedaluminum、lightglint脉冲移动等)及调高光影采样精度等高级参数,提升内置金属光学模拟效果。
-

CodeBuddy提供五种重构路径:一、Web界面上传分析;二、CLI批量自动化重构;三、IDE插件上下文感知重构;四、Craft智能体自然语言驱动重构;五、自定义指令流水线。
-

可灵AI提供三种全家福转动态视频方案:一是单图生成自然微动视频;二是多图驱动构建三维家庭聚会场景;三是API定制化编排动作与语音同步。
-

需校验基座生命周期钩子、子应用独立运行与沙箱兼容性、路由前缀与通信协议同步、qiankun沙箱启用及WorkBuddyAgent自动化诊断,五步闭环排查微前端加载异常。
-

如果您在可灵AI中生成了人物视频,但尚未为其添加匹配语音与口型动作,则需通过配音与同步流程实现“说话”效果。以下是完成中文语音合成及口型精准对齐的具体操作路径:一、使用可灵AI内置文本转语音(TTS)配音该方式适用于无现成音频、仅凭文案生成语音与口型的场景,系统自动调用中文TTS引擎并驱动唇部动画,无需外部文件介入。1、进入可灵AI视频编辑界面,确保已生成含清晰人脸的人物视频(支持真实人像、2D/3D角色)。2、点击底部工具栏中的“配音”按钮,切换至“文字配音”模式。3、在文本输入框中粘贴标准