-

文本到图像的扩散生成模型,如StableDiffusion、DALL-E2和mid-journey等,一直都处于蓬勃的发展状态,有着极强的文本到图片的生成能力,但是「翻车」案例也会偶尔出现。如下图所示,当给定文字提示:「Aphotoofawarthog」,StableDiffusion模型能生成一张相应的、清晰逼真的疣猪照片。然而,当我们对这个文本提示稍作修改,变为:「Aphotoofawarthogandatraitor」,说好的疣猪呢?怎么变成车了?一起再来看一看接下来的几个例子,这些又是什么新物种?
-
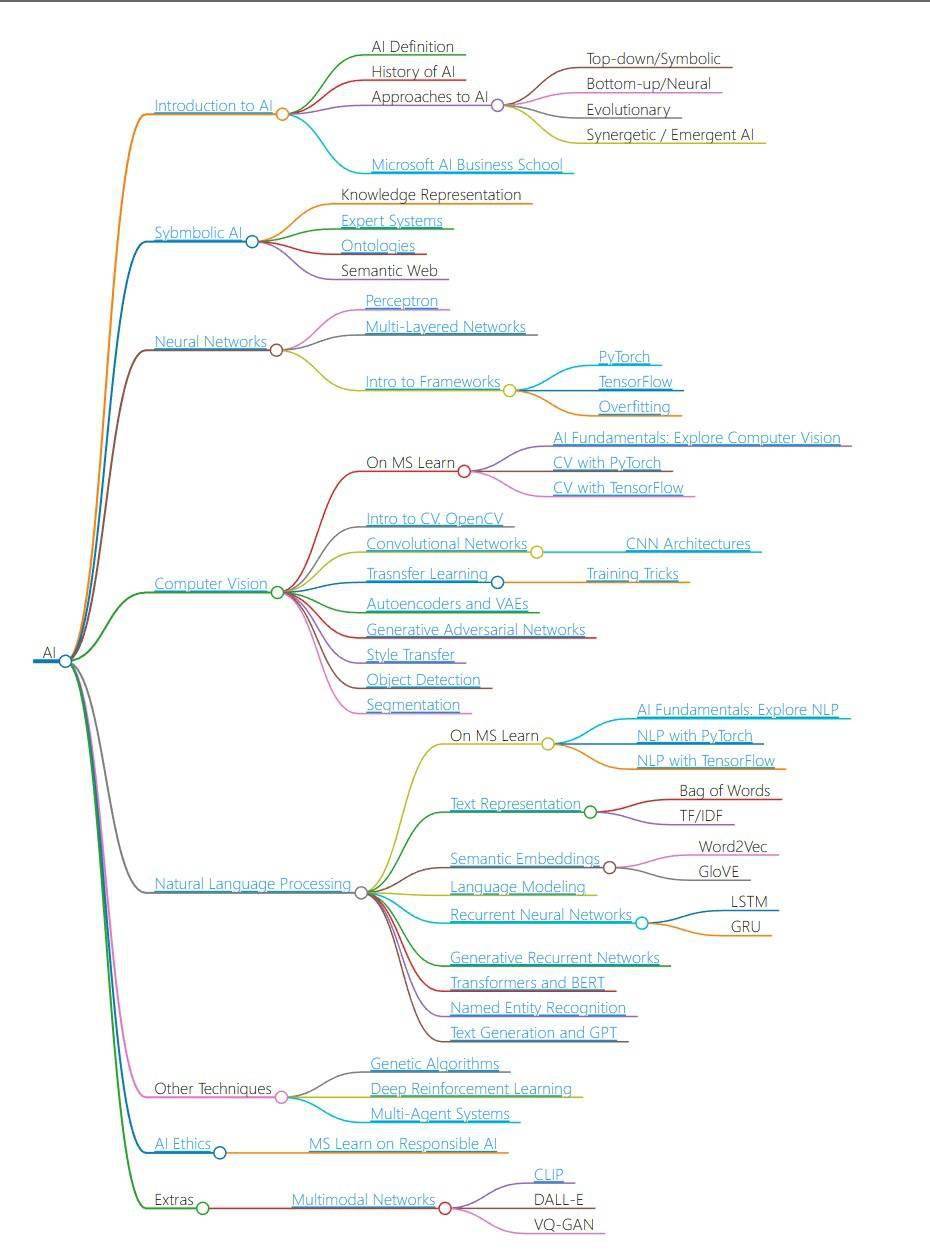
IT之家6月15日消息,微软目前为AI初学者推出了一套免费网课,该课程为期12周,共包含24节课。据悉,该课程是对人工智能的“大起底”,微软在网课中探讨了神经网络和深度学习的相关原理及知识,可令用户知悉用于处理图像和文本的神经架构,并了解到一些“不那么流行”的人工智能方法,IT之家的小伙伴们可以在这里访问该网课内容。微软表示,在本课程中,大家可以学习到:人工智能的不同方法:包括知识表示和推理(GOFAI)的“老式”符号方法。神经网络和深度学习:将使用流行框架TensorFlow和PyTorch中的代码来介
-

从机器学习工程师到数据科学家,以下是2023年5大人工智能职业。对于那些在不断扩大的人工智能领域工作的人来说,这是个好消息,因为人工智能职业前景看好,数据科学家和机器学习工程师位居榜首。根据美国劳工统计局(BLS)的数据,预计在2021年至2031年间,计算机和信息研究科学家的就业人数将增长21%,其中包括人工智能方面的机会。这比平时快多了。考虑到最近人工智能热潮期间ChatGPT的发展,不妨考虑从事人工智能职业。现在我们来了解一下从事的人工智能工作以及所需要的资格。1、人工智能工程师人工智能工程师是使用
-

国内机器人联盟(IFR)将机器人分为工作机器人、服务机器人和特种机器人三类。服务机器人已经在餐饮和酒店等场景广泛应用,并成为一道美丽的风景。根据行业数据显示,中国作为服务机器人的发源地,也是全球最大的服务机器人市场服务机器人行业的竞争主要取决于技术实力、产品品质和运维网络的覆盖范围。经过多年的竞争,国内服务机器人行业出现了明显的两极分化,一些头部厂商脱颖而出,占据了大部分市场份额IDG的数据显示,擎朗和高仙自动化公司堪称商用服务机器人的“双雄”:擎朗占据餐饮机器人市场第一;而在清洁机器人领域,高仙自动化公
-

萤石网络是一家领先的品质智能家居品牌。凭借出色的产品、质量和服务,萤石网络成为首批获得物联网产品网络安全认证的企业,并且还获得了中国质量检验协会颁发的四项全国质量荣誉证书在第五届中国质量大会“质量之光——中国质量管理与质量创新成果展”上,萤石与小度、小米、联想、科大讯飞、字节跳动等共6家品牌的相关物联网产品获颁首批物联网产品网络安全认证证书。此次认证的权威机构——中国质量认证中心(CQC),隶属于中国检验认证集团。CQC联合国家电子计算机质量检验检测中心推出的“物联网产品网络安全认证项目”,聚焦产品网络安
-

·富士康宣布,将使用英伟达芯片和软件建造新型数据中心,用于包括自动驾驶汽车、自主机器人和工业机器人在内的开发。英伟达CEO黄仁勋表示,两家公司将共同建造这些“人工智能工厂”。·黄仁勋所说的“人工智能工厂”预计将成为特斯拉Dojo超级计算机的直接竞争对手。Dojo被用于训练特斯拉的神经网络,这些神经网络用于支持、训练和改进其“全自动驾驶”。英伟达CEO黄仁勋和富士康董事长刘永威在富士康年度科技展示会上同台。10月18日,身穿标志性黑色皮夹克的英伟达CEO黄仁勋又一次出现在台北,这次是和富士康董事长刘永威在富
-

企业如何使用人工智能解决方案来提高效率和简化流程?随着人工智能解决方案的发展,越来越多的企业采用新的战略来更好地满足客户需求,提高运营绩效和财务业绩。本文将介绍人工智能驱动的解决方案的常见用例,如自然语言处理、认知计算、机器学习和数据分析,并描述它们对企业的潜在好处探索人工智能解决方案的潜力随着技术的不断进步,企业一直在寻找创新的方式来发展和保持竞争力。人工智能解决方案已经成为实现这一目标最有前途的途径之一,因为它能够简化流程、改进决策并增强客户体验。通过利用机器学习、自然语言处理和数据分析等人工智能解决
-

IT之家11月15日消息,Varjo是一家专注于高端企业级XR头显的制造商,该公司的头显拥有独特的“仿生显示”系统,每个镜片的中心区域能提供视网膜级的分辨率。该公司还致力于开发高质量的透视功能和利用透视功能的创新特性,其旗舰头显XR-3于2020年底发布。VarjoXR-3拥有业界最高的分辨率,其使用了人眼仿生技术,使其在115°的视野范围内达到70PPD人眼分辨率,从而提供很好的真实感和可见性;除了能够匹配99%以上SRGB色彩空间反映现实世界之外,还集成眼动追踪(200Hz)和Ultraleap(v5
-

11月27日,2023山东省食品安全宣传周“食安山东”媒体行采访团来到滨州探访智慧食安指挥服务平台。在滨州市大数据局和大数据中心的支持下,"智慧食安"指挥服务平台项目于2023年3月在滨州全市开始使用。自"智慧食安"指挥服务平台全面应用以来,已经成功采集了滨州全市14072家重点食品经营企业的数据,并获取了1041名食品安全员和从业人员的健康信息。平台还发现了超过6000次的违规操作,并向企业发出了超过1万次的预警和规范经营告知。通过"智慧食安"平台的应用,滨州全市的餐饮食品安全水平得到了整体提升据介绍,
-

谷歌制定新“机器人守则”确保科幻片不会成真DeepMind机器人团队最新公布了三项新进展,旨在帮助机器人在实验室外做出更快、更好、更安全的决策。其中之一是他们开发了一个系统,通过“机器人守则”收集训练数据,以确保机器人办公室助理可以为用户取更多的打印纸,但同时避免攻击碰巧挡道的人类同事。这一进展将进一步提升机器人的工作效率和安全性。谷歌的数据收集系统AutoRT利用视觉语言模型(VLM)和大型语言模型(LLM)协同工作,以了解环境,适应陌生的情境,并决定适当的任务。这个系统的设计灵感来自于阿西莫夫的《机器
-

马尔可夫过程是一种随机过程,未来状态的概率只与当前状态有关,不受过去状态的影响。它在金融、天气预报和自然语言处理等领域有广泛应用。在神经网络中,马尔可夫过程被用作建模技术,帮助人们更好地理解和预测复杂系统的行为。马尔可夫过程在神经网络中的应用主要有两个方面:马尔可夫链蒙特卡罗(MCMC)方法和马尔可夫决策过程(MDP)方法。下面将简要介绍这两种方法的应用示例。一、马尔可夫链蒙特卡罗(MCMC)方法在生成对抗网络(GAN)中的应用GAN是一种深度学习模型,由生成器和判别器两个神经网络组成。生成器的目标是生成
-

5月30日,社交平台Soul+App在上海举办媒体开放日活动,以“人与人工智能是否能够成为‘朋友’”为主题,分享了平台前沿技术探索和最新产品应用实践,并邀请了复旦大学教授肖仰华以及众多行业观察者,一同探讨AIGC+社交的应用及未来发展可能性。媒体开放日活动是Soul与外界达成长效、深度链接的重要桥梁。在AI为各行各业带来颠覆式发展的当下,Soul作为“AIGC+社交”领域前沿探索者,希望通过本次活动,全面展示Soul在AI方面的技术积累及落地实践,为行业提供可行的发展方向参考。模应一体:AI重构关系链与社
-

大模型也可解释了?大模型都在想什么?OpenAI找到了一种办法,能给GPT-4做「扫描」,告诉你AI的思路,而且还把这种方法开源了。大语言模型(LLM)是当前AI领域最热门的探索方向,吸引了大量的关注和研究投入。它们强大的语言理解能力和生成能力在各种应用场景中都表现出巨大潜力。虽然我们已经证实了大模型迭代后性能能够显著提升,但我们目前对模型中的神经活动仍然只是一知半解。据报道,OpenAI分享了一种全新的查找大量“特征”的方法,或许这会成为可解释的一种可用方向。OpenAI表示,新方法比此前一些思路更具扩
-
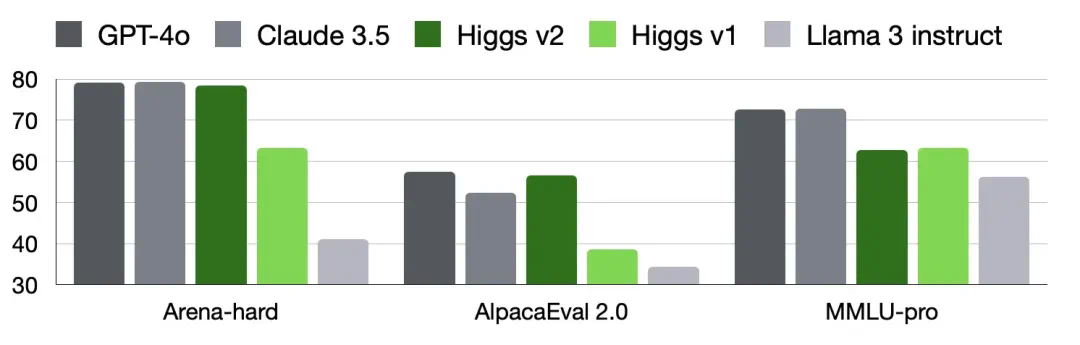
给小伙伴汇报一下LLM创业第一年的进展、纠结和反思。在Amazon呆到第五年的时候就想着创业了,但被疫情耽搁了。到第7年半的时候,觉得太痒了,就提了离职。现在想来,如果有什么事这一辈子总要试下的,就蹭早。因为真开始后会发现有太多新东西要学,总感叹为啥没能早点开始。名字:BosonAI的来源创业前做了一系列用Gluon命名的项目。在量子物理里,Gluon是把夸克绑在一起的一种玻色子,象征这个项目一开始是Amazon和Microsoft的联合项目。当时项目经理拍拍脑袋名字就出来了,但取名对程序员来说很困难,我
-

10月30日,《哈佛商业评论》2024中国年会暨“拉姆·查兰管理实践奖”颁奖典礼在北京成功举办。由清华大学经济管理学院中国工商管理案例中心推荐、中兴通讯的两项管理实践案例双双获奖:《中兴通讯:提升企业韧性,一流合规体系的建设之道》和《中兴通讯:与“不确定性”共舞,供应链的战略重塑》荣获2024拉姆·查兰管理实践奖——杰出奖。“拉姆·查兰管理实践奖”由《哈佛商业评论》中文版主办,代表着中国管理实践的至高荣誉。该奖项集结了中国顶级商学院组成的强大评审阵容,由数十位知名教授、学者全方位研讨企业案例,从数百余篇案