-

要实现Zapier多用户共享,需升级至团队或企业版计划,创建团队并邀请成员分配角色,将个人Zaps移入团队空间以共享,并通过创建共享文件夹分类管理自动化流程,提升协作效率。
-
使用夸克AI可实现文档、网页及图片翻译:①在App内使用“文档翻译”功能上传文件并选择目标语言;②通过夸克浏览器调用“网页翻译”实时转换页面内容;③使用“扫描王”对纸质文档进行OCR识别后翻译,支持文本对照与导出。
-

明确角色、任务、格式与限制是设计高效提示词的关键。先定义AI身份如“营养学专家”,再具体化任务目标、受众和场景,避免模糊指令;接着指定输出结构,如分点、表格或段落要求,确保结果可直接使用;然后添加字数、风格、禁用内容等约束条件,防止偏离主题;最后可通过示例示范语气与格式,引导AI精准模仿。通过系统化构建这四个维度的指令,提示词将从试错变为精准导航,使AI输出稳定符合预期。
-

PaperOK查重系统官网为https://www.paperok.com,提供登录注册、免费积分领取、文档上传检测、报告查看下载等功能,整合多类学术资源库,覆盖期刊论文与网络信息,采用语义分析与分段检测技术,支持学科分类更新与引用标注建议,提升查重精准度。
-

要实现AI模型材料选择工具与豆包的有效协作,核心在于构建标准化的数据交换协议和智能化的交互逻辑。首先,AI工具需提供稳定API接口,接收用户需求参数并返回结构化材料推荐结果;其次,豆包需具备意图识别能力,将自然语言转化为API参数,并解析结果以用户友好的方式呈现;此外,还需建立错误处理机制,提升系统鲁棒性;最后,通过定义“中间数据契约”实现数据格式的翻译与标准化,确保双方理解一致;在交互设计上,豆包应优化Prompt策略,增强对话引导与结果展示能力;集成过程中可能面临数据同步、API稳定性、复杂查询映射等
-

可灵AI支持多格式导出,满足不同使用需求:进入作品详情页点击“导出”,选择MP4(适合社交媒体)、GIF(用于表情包)、MKV/MOV(高质量后期编辑)或JSON元数据(便于归档协作),调整分辨率、帧率等参数后生成下载链接,建议根据场景选择合适格式并提前确认设置以避免重复操作。
-

腾讯元宝可生成个性化学习计划,首先明确学习者身份、水平、目标和周期,输入具体指令;其次启用“满血版DeepSeek”模式提升生成质量;再通过追加分阶段结构与动态调整规则增强计划弹性;接着融合跨学科资源与实践任务提高实用性;最后导出计划并根据执行反馈持续优化。
-

11月29日,东风奕派正式发布消息,旗下全新高性能轿跑车型eπ007+将于2025年11月10日迎来上市。作为一款中大型纯电动轿车,新车在外观造型、智能科技以及动力系统等方面实现了全方位进化。东风奕派eπ007+据官方公布的数据,东风奕派eπ007+的车身尺寸为长4880毫米、宽1915毫米、高1476毫米,轴距达2915毫米,呈现出修长而协调的比例设计。车辆采用黄金比例布局,并搭配全新样式的轮毂设计,显著增强了整体的视觉冲击力,无论静止还是行驶中都极具动感气质。此外,全系标配随车速自动调节的电动尾翼,不
-

文心一言AI生成器入口在官网https://yiyan.baidu.com,支持多模态内容生成、智能对话交互及跨设备在线使用,具备图像生成、上下文理解与历史记录保存等功能。
-

使用即梦提升图片清晰度需先开启超分辨率增强,再调节锐化至60-80,结合AI细节修复与多帧融合技术,可有效改善低分辨率、模糊及噪点问题,增强图像细节表现力。
-

可借助AI配色工具快速生成专业配色方案:一、AdobeColorAI依图像或关键词提取主色并导出CSS;二、Coolors.coAI依描述生成高对比度配色;三、GalileoAI在Figma中一键应用配色;四、ColorMind开源模型支持本地离线预测。
-

AI工具可快速生成专业简历,路径包括:一、使用“超级简历”等垂直平台,输入信息后智能生成并优化;二、调用大模型API嵌入表单,按STAR法则生成结构化内容;三、利用WPS或Word内置AI实时生成与润色。
-

Kimi智能助手提供五步基础使用指南:一、通过网页/APP/小程序任一入口访问;二、上传最多50个文件(≤100MB)供解析;三、输入@Kimi+调用24类垂直智能体;四、设置常用语实现指令一键触发;五、在App中克隆声音并启用语音播报。
-
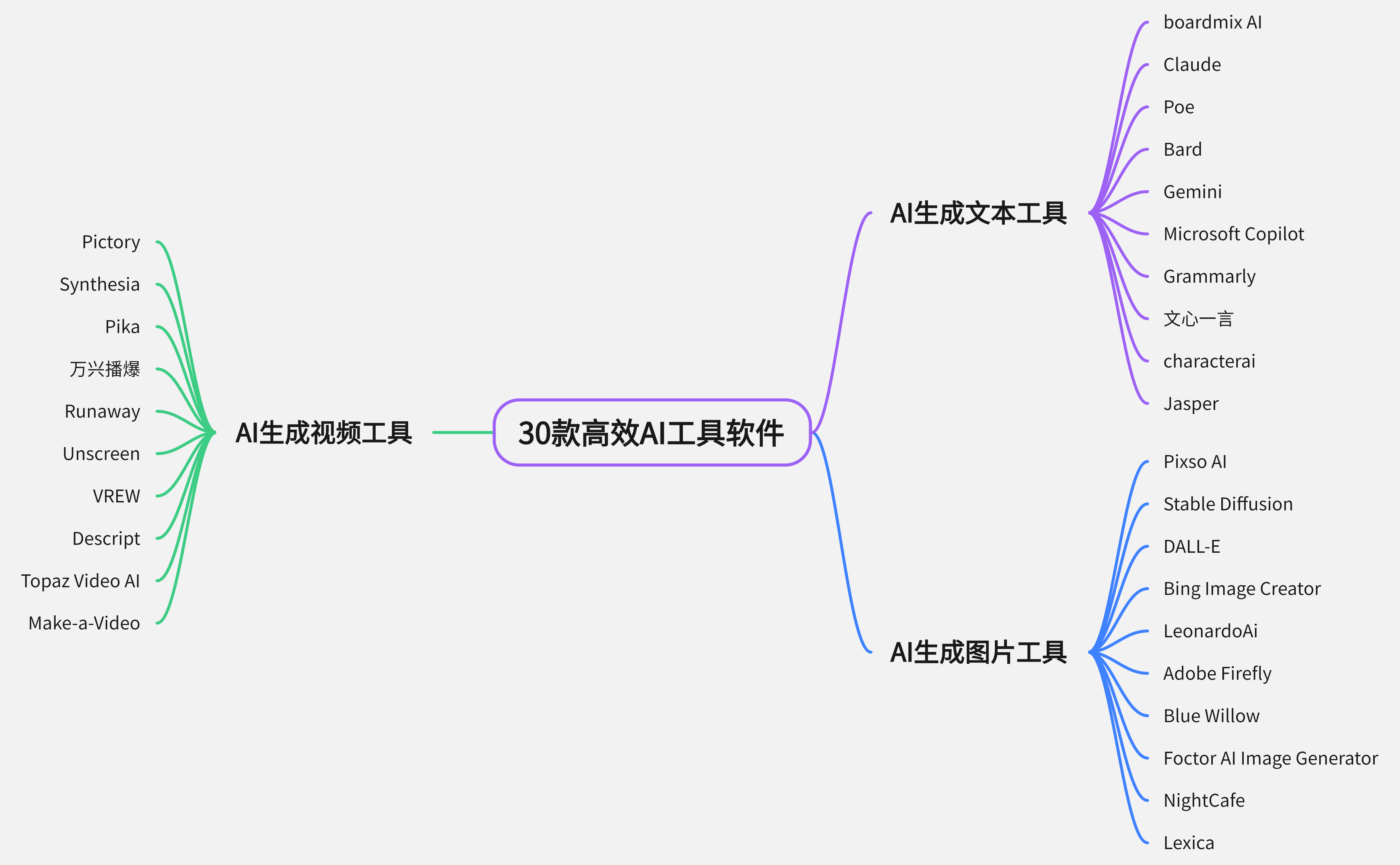
启用CustomInstructions可提升ChatGPT回答质量:一、填写基础身份信息;二、设定回答风格与输出约束;三、注入高频任务模板;四、隔离干扰性默认行为;五、验证与快速迭代配置。
-

ChatGPT4o可通过五种方法高效辅助GRE词汇复习:一、生成跨学科例句与语境填空;二、构建主题式同义/反义网络图;三、解析GRE阅读长难句中的词汇功能;四、启动错词驱动的动态复习路径;五、生成带音标与节奏标记的语音跟读脚本。