-

OpenClaw存档管理包含四种方式:一、手动定位备份存档文件至指定路径;二、通过F5/F8快捷键及图形界面进行保存加载;三、用--save-dir命令行参数自定义存档目录;四、导入校验后的.clawpkg存档包。
-

必须放参考样例,但须满足“真实数据+时间标注”双条件;无数据锚点的样例会导致AI泛化模仿,稀释风格。
-

千问与淘宝全面打通,5月11日上线全球首个AI购物全链路闭环:用户一句话即可在千问App或淘宝“千问AI购物助手”中完成商品挑选、对比、下单、试穿、算优惠及售后,依托淘宝40亿商品库与20年场景数据实现精准推荐与智能决策。
-

页脚仅出现在PPT每页底部居中区域,高度≤0.8厘米,微软雅黑9号、#666666色;内容限三类之一(≤12字结论/数据来源/执行提示),禁跨页指代、人称代词及动词原形句;须锚定本页主标题与首段正文,短文本或特殊标点时强制留空。
-

豆包AI视频理解需启用专属模式并输入结构化指令:确认MP4/MOV原生视频或合规平台链接,点击「视频理解」按钮,严格按五部分输出语音转文字、关键画面、面部朝向、音乐情绪、字幕文本,开启多帧采样增强动作识别,人工校验音画同步,导出CSV标记导入剪辑软件。
-

平滑迁移老版本DeepSeek模型需分三类场景:一、手动迁移配置与权重,复用旧文件并校验兼容性;二、通过HuggingFaceAutoModel桥接,利用transformers向后兼容机制自动映射架构;三、LoRA微调参数绑定式迁移,合并适配器后验证logits一致性。
-

WorkBuddy提供四种CSV合并方法:一、数据集合并功能批量导入并按行追加;二、SQL脚本用UNIONALL精确控制合并;三、模板映射统一字段语义后批量导入;四、Python脚本自定义清洗与合并。
-

若已用Trae开发项目但未生成文档,需补全代码注释、统一Markdown格式输入、调用Agent生成校验文档、启用Git增量更新、嵌入代码块自动化测试验证。
-

即梦AI实现人物飞天升空需四法:一、文生视频用精准提示词+Seedance2.0生成动态升空;二、图生视频上传舒展原图+力与空间提示词强化动势;三、分阶段用Seedream5.0起势、扩图留白、Seedance2.0驱动动画;四、预设角色后调用动作编码指令直触升空内核。
-

OpenClaw通过五类机制实现工具调用错误重试:一、按Telegram/Discord等通道差异化配置重试参数;二、依HTTP状态码(如429、503)智能触发重试;三、限定重试粒度为单请求,保障幂等性;四、利用before_tool_callHook动态注入重试逻辑;五、通过Cron调度自动重试失败任务并告警。
-

需安装Node.jsv18+,执行平台专用安装脚本,启动openclaw服务后访问http://localhost:18791配置MoonshotAIProvider并验证三层连通性。
-
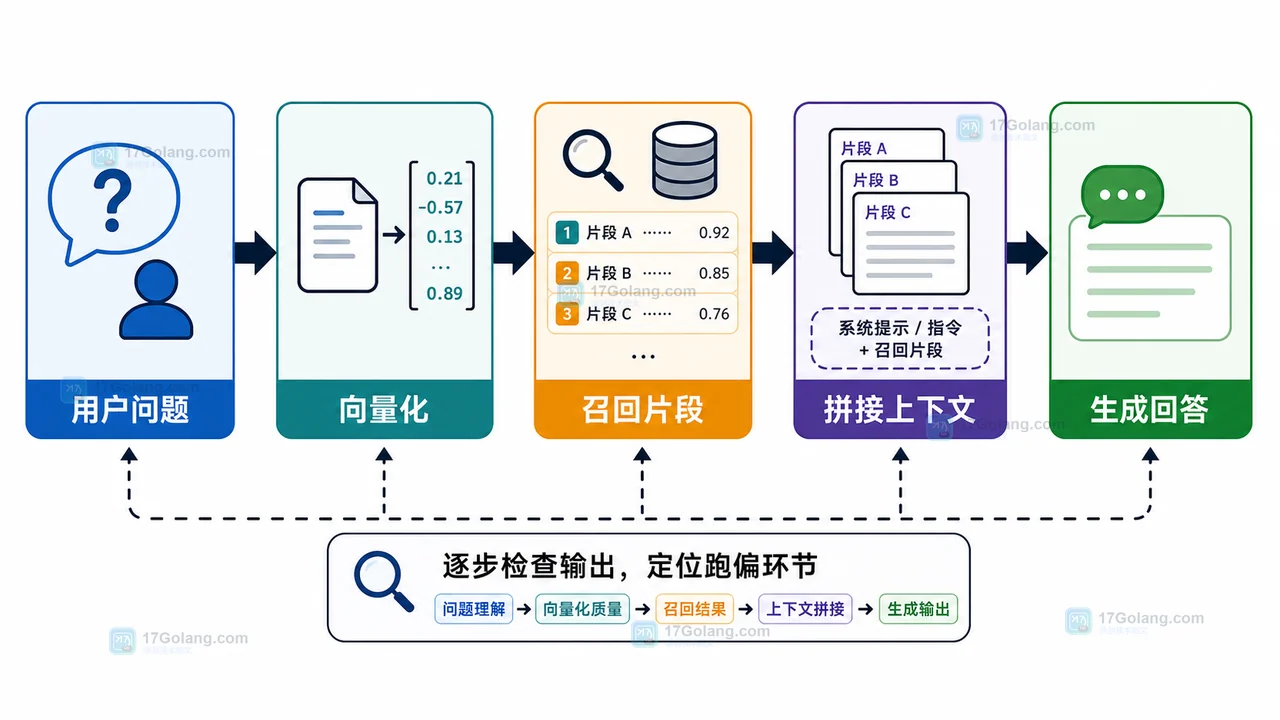
从 RAG 应用答非所问的现场出发,逐步检查文档切块、Embedding、向量召回、混合检索和上下文拼接,给出一套可复查的排查路径。
-

若缺乏Gemini模型系统性学习渠道,可加入其官方协作学习环境:一、访问gemini.google.com/learn并点击“Joincommunity”;二、通过groups.google.com/g/gemini-learners申请加入讨论组;三、在GitHub关注generative-ai-examples仓库并参与Discussions;四、注册events.google.com/gemini-office-hours参加每月线上OfficeHours。
-

需使用即梦AI5.0纪录片增强模式,构建四维提示词,上传双参考图,启用首尾帧控制,并加载“柴窑纪实”Lora插件(企业版),方可精准生成陶瓷碗出窑升雾、匠人凝视的纪录片风格视频。
-

使用通义万象生成童话插画需五步:一、构建具象化提示词并添加风格短语;二、调高风格强度至75%–90%,选用插画模型与合适分辨率;三、用负向提示词排除写实、现代等干扰元素;四、对局部不理想处进行定向重绘;五、以标准像为基准批量生成连贯场景。