-

要实现烟雾缭绕的仙境氛围,需优化提示词结构嵌入专业雾气描述符、选用适配的模型版本与参数组合、采用分阶段生成+后期雾层叠加法,或直接调用即梦内置“仙境雾霭”特效。
-

需注册RecraftAI账号方可使用全部功能:一、访问官网recraft.ai确认标识与登录按钮;二、点击“Signin”后选“Createaccount”;三、填有效邮箱、强密码并同意协议;四、查收验证邮件并点击链接完成验证;五、遇403错误需检查邮箱验证、API权限及Workspace角色;六、表单无响应时应清缓存、禁插件、换浏览器或净化字符。
-

如果您希望获取AI软件免费版,但不确定从何处下载或如何正确安装,则可能是由于官方渠道未明确标识“免费版”入口,或第三方来源存在混淆。以下是针对主流AI设计类与AI图像处理类软件免费版本的获取与安装步骤:一、AdobeIllustrator2025中文免费版下载与本地安装该版本为非订阅制独立安装包,含完整功能且无需联网激活,适用于Windows系统。安装前需确保关闭所有实时防护程序以避免误删关键文件。1、访问可信技术资源站点,下载名为“AdobeIllustrator2025中文免费版v2
-

CodeBuddy支持五种本地代码安全检测路径:一、启用内置CodeVulnScannerAISkills实时扫描;二、通过OpenClawCLI执行语言指定深度审计;三、配置定时扫描与Git门禁拦截;四、对接SonarQube实现规则融合与联合分析;五、在Lighthouse沙箱中隔离运行高危代码并生成行为指纹。
-

对话记录消失可按五步恢复:一、展开左侧历史栏并强制刷新;二、确认登录账号一致;三、通过会话ID或LocalStorage中“conversations”手动访问存档;四、从LocalStorage的“pendingMessages”或“drafts”提取未同步草稿;五、禁用拦截扩展排查网络干扰。
-

若唐库AI拆书任务无响应,应先通过任务中心查状态,再观察目录序号变化,接着用开发者工具检查网络请求,然后核对AI模型配额与日志,最后可强制终止并重试。
-

需完成API密钥配置、前端SDK加载、后端代理设置、UI定制与事件钩子、Webhook接收验证五步:一、在开发者平台创建绑定域名的API密钥并存入环境变量;二、通过script加载SDK并在HTTPS页面初始化聊天窗口;三、用Node.js搭建代理路由透传请求并流式转发SSE响应;四、通过init配置theme样式及onMessageSent/Received钩子实现UI统一与行为捕获;五、配置Webhook地址,用HMAC-SHA256校验签名并返回200确认。
-

可通过四种方法在手机浏览器中直接使用Duck.ai:一、在DuckDuckGo首页搜!ai跳转;二、手动输入duck.ai并启用桌面模式;三、用自定义书签强制桌面UA;四、通过Kiwi等支持扩展的浏览器安装快捷插件。
-

可借助插件或脚本实现多行文本图层按行自动编号命名:一、“RenameIt”拆分文本为独立图层并命名;二、“AutoLayoutRenamer”统计行数重命名原图层;三、FigmaAPI脚本创建带编号的新文本图层;四、手动“转轮廓”后逐层重命名。
-

要稳定生成15秒完整视频,须选用“全能参考模式”,上传≤12个多模态素材,编写五要素分镜头提示词,正确使用@绑定素材,并启用Fast加速通道。
-

通义万相中实现分层飞散视差效果需结合语义分割、结构化提示词或本地Z-Image协同:一用局部重绘分层提取;二靠多阶段提示词驱动飞散;三借Z-Image精控轨迹与物理噪点。
-

海螺AI生成4K视频需四步:一查账户权限与UltraHD-4K模型;二在Prompt末尾用自然语言声明“输出分辨率:3840×2160,4K超高清”;三调用API时JSON中设video_resolution为"3840x2160"并配ultra画质与25000码率;四验证输出MP4属性是否为3840×2160且编码为H.265/HEVCMain10。
-
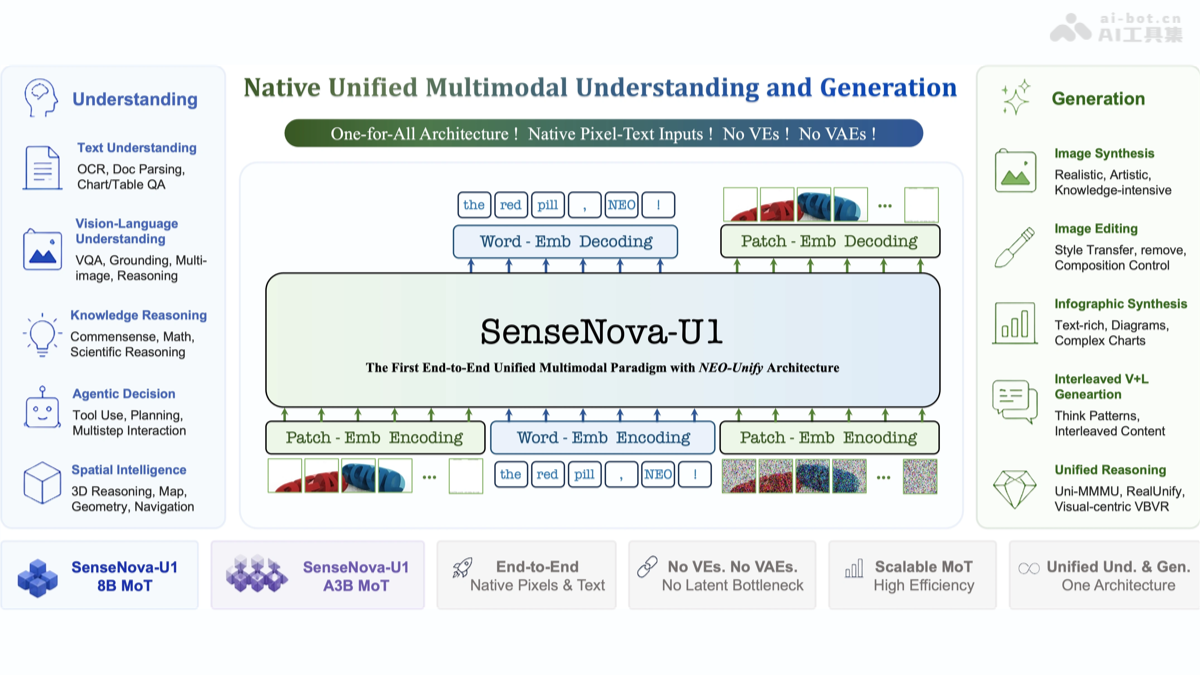
SenseNovaU1是商汤科技日日新平台推出的原生统一多模态大模型,基于其于2026年3月自主研发的NEO-Unify架构构建。该模型在单一神经网络结构中深度融合语言与视觉信号,首次实现理解、推理与生成能力的原生一体化,突破传统拼接式多模态架构的固有瓶颈。SenseNovaU1的核心能力多模态深度理解:全面支持高精度OCR、复杂文档解析、图表语义问答、跨图像逻辑推理及细粒度视觉问答(VQA)。高质量图像生成:可生成写实场景、艺术风格及知识密集型图像(如带标注的科学示意图),并具备
-

StyleSync可实现Figma图层名称与DesignTokens自动双向同步:一、安装插件并初始化映射;二、配置正则规则绑定命名与Token;三、批量校准不规范图层名;四、启用实时监听同步;五、导出带图层路径的TokensJSON供开发使用。
-

Canva兼容性问题源于设备未达官方硬件与系统门槛:桌面端需Chrome110+/Win1020H2+/4GBRAM及WebGL2支持;桌面客户端要求AVX2CPU、Metal/OpenGL4.1+显卡;安卓需ARMv8+处理器及Android8.0+;iOS限A9芯片及iOS14+;华为HarmonyOS需MatePadPro系列及3.0+系统。